




Cerebras Systems: פתרון חדשני לעומסי עבודה בבינה מלאכותית ו HPC.
בעשור האחרון, הביקוש לבינה מלאכותית בקנה מידה רחב הביא את מעבדי ה GPU לגבול היכולת שלהם. בעוד גישות מסורתיות מתקשות לעמוד בצרכים של מודלים גדולים, פתרונות חדשניים מבוססי חומרה ייעודית מציעים חלופה אטרקטיבית: יותר ביצועים, פחות מורכבות ועלויות תפעול מופחתות.
בכתבה זו נסקור כיצד מערכות כמו אלו של Cerebras מובילות את השינוי — ומאפשרות לעולם הבינה המלאכותית לעשות את הקפיצה הבאה.
העניין והעיסוק הרחב כל כך סביב הבינה המלאכותית ברורים לכולם. באופן ספציפי, ההתעניינות והשימוש הנרחב התעורר בשנתיים וחצי האחרונות בעקבות הבינה המלאכותית היוצרת (Generative AI), שבה רשתות עצביות מלאכותיות הותאמו מחדש ממשימות סיווג ליצירת תוכן. ChatGPT ומוצרים דומים הפכו לשמות מוכרים במהירות רבה. ההשפעה על הכלכלה ועל חיי כולם מבטיחה להיות משמעותית מאוד, ולכן אי אפשר להתעלם מהטכנולוגיה הזו.
ישנם לא מעט חידושים שעומדים בבסיס ההצלחה של ChatGPT ודומיו, אך כאן אנו רוצים להתמקד באתגרים המחשוביים הקשורים לרשתות עצביות מודרניות או מודלים שפתיים גדולים כמו Generative Pre-trained Transformer 4.5 (GPT 4.5) שמפעיל את ChatGPT כיום. כדי לעשות זאת, הגיוני לחזור אחורה ולהתבונן בתעשיית הטלקומוניקציה השכנה.
באוקטובר 2012, קבוצת מפעילי טלקום מובילים פרסמה מסמך עמדה בו נטען למעשה כי תעשיית הטלקומוניקציה אינה יכולה ואינה צריכה להתמודד יותר עם חומרה ייעודית. הם לא יכלו להתמודד עם מצב שבו ספקי טכנולוגיית טלקומוניקציה עיצבו את כל ה stack מהמעבד ועד שכבת הווירטואליזציה ומערכת ההפעלה המיוחדת ולבסוף עד סוג מסוים של תוכנה מיוחדת שמבצעת פונקציה רלוונטית ברשת – למשל טיפול באיתותים של רשת התקשרות. גישה זו עיכבה את החדשנות בתעשיית הטלקומוניקציה, שבה השחקנים החלו להרגיש את הלחץ התחרותי מטלפוניית IP, נטפליקס (שהחלה להזרים תוכן בשנת 2007) וכו'. באותו זמן, התעקשו טכנולוגים מ-13 חברות הטלקום הגדולות כי שרתי CPU מבוססי מעבדי X86 חזקים מספיק כדי להתמודד בקלות עם עומסי העבודה של רשתות התקשורת, ולטענתם זה היה נכון לכל עומסי העבודה, שכן עומסי העבודה של רשתות אלה נתפסו כקשים ביותר. מסמך זה היה רגע מכריע שבו שרתי CPU הוכתרו כמלכים וחומרה ייעודית החלה להידחק מחוץ לרשתות התקשורת והגישה המכונה Network Function Virtualization נולדה בתעשיית התקשורת.
האירוניה בסיפור הזה היא שרק כמה ימים לפני כן אלכס קריז'בסקי יחד עם איליה סוטסקבר והמנחה שלו לדוקטורט ג'פרי הינטון הגישו את AlexNET – ארכיטקטורת רשת עצבית קונבולוציונית למשימות סיווג תמונות שרצה על יחידות עיבוד גרפי (GPUs) – לתחרות ImageNet Large Scale Visual Recognition Challenge, שבה AlexNET זכה בהפרש משמעותי. בכך הם הציגו משפחה חדשה של עומסי עבודה שהייתה מיד בלתי מעשית על CPUs ודרשה פלטפורמת מחשוב חדשה ש-GPUs סיפקו באותה תקופה.
הרשתות העצביות של היום שמפעילות מודלים שפתיים גדולים הן צאצאים של AlexNET, וגם הן מסתמכות על GPUs לאימון והסקה. אבל הבעיה העתידית כבר נראתה עם AlexNET. אפילו AlexNET הקטן יחסית לפי הסטנדרטים של היום (60 מיליון פרמטרים) לא התאים ל-GPU אחד והיה צריך לחלק אותו בין שתי יחידות. בקפיצה מהירה קדימה ל-2023 ו-GPT-4, שלפי השמועות כולל מעל טריליון פרמטרים, מתאמן על אלפי GPUs במשך חודשים. אז שוב הגיע הזמן לתהות אם עומס העבודה הגדול הזה מתאים למעבד הנבחר – GPU.

תמונה Wafer Scale Engine WSE-3 :1 קרדיט: Cerebras Systems
הבעיה באה לידי ביטוי במספר הכותבים בדוח הטכני של GPT-4 ([2303.08774] GPT-4 Technical Report) – יותר מ-200 כותבים בדוח הטכני של המודל, כולל בין 20 ל-30 (תלוי איך סופרים) אנשי מקצוע בתחום ההנדסה המקבילית. חלוקת המודלים, בנייה ושחזור גישות מקביליות לאימון היא מאוד מסובכת ולוקחת זמן רב והיא יקרה מאוד. לדוגמה, ניתן לתאר את מודל GPT עם 175 מיליארד פרמטרים בפחות מ-600 שורות קוד ב-PyTorch – שפת הבינה המלאכותית – אבל עבודת המקביליות עבור GPUs תדרוש למעשה עוד 20,000 שורות (!) קוד ספציפיות ל-CUDA עבור GPUs.
בנוסף לכך, ארכיטקטורת החומרה התומכת באשכולות האימון מבוססי GPUs כוללת רשת אינפיניבנד יקרה מאוד, מספר רב מאוד של מכשירים הרגישים לתקלות וכו'. בפועל, המשמעות היא שבניית מודלים גדולים חדשים ואימונם על GPUs הופכת לבלתי אפשרית מחוץ למספר קטן מאוד של מעבדות מדעי מחשב מתקדמות עם כוח אדם יקר מאוד. זה לא נשמע כמו שה-GPU הוא המעבד הטבעי לעומסי העבודה המודרניים של AI. יתר על כן, בשל המפרט הבסיסי כמו גודל פיזי ומיקומים יחסיים של מודולי מחשוב וזיכרון ב- GPU ) GPUs אינו שבב בודד, אלא מספר שבבים על אותו לוח), לא ניתן לפתור את המגבלות הקיימות רק על ידי ייצור גרסאות נוספות של אותו הדבר.
אלן קיי, מדען מחשבים מפורסם, אמר: "אנשים שבאמת רציניים לגבי תוכנה צריכים לייצר חומרה משלהם".
כאן נכנסת לתמונה חברת Cerebras Systems. החברה נוסדה בקליפורניה בשנת 2016 על ידי צוות מהנדסי מחשבים ומעבדים בעלי ניסיון רב והצלחות בתחום המעבדים והשרתים. המשימה שלהם הייתה לעצב מעבד ומערכת סביבו שמתאימים לעומסי העבודה ההולכים וגדלים בבינה מלאכותית ולדור הבא של מחשוב עתיר ביצועים, HPC.
התוצאה היא Wafer-Scale Engine 3 (WSE-3), הדור השלישי של המעבד הגדול והחזק ביותר שנבנה אי פעם עבור בינה מלאכותית. המעבד WSE-3 גדול פי 57 מה-GPU הגדול ביותר בשוק, גודלו46,250 מילימטרים רבועים והוא כולל 900,000 ליבות אופטימליות לבינה מלאכותית (פי 52 מ GPU ברמה הגבוהה ביותר). הוא מציע on-chip core-to-core fabric ברוחב פס אדיר של 30 פטה-בתים לשנייה בין הליבות ומכיל זיכרון SRAM בנפח 44GB על השבב עצמו (פי 440 מ GPU) כמו גם רוחב פס זיכרון ללא תחרות של 25 פטה-בייט לשנייה (פי 2600 יותר מ GPU המתקדם ביותר).
על ידי יצירת ה WSE, Cerebras פתרה כמה מהאתגרים המורכבים ביותר של תעשיית המוליכים למחצה, וסיפקה יותר כוח מחשוב, רוחב פס תקשורת ורוחב פס זיכרון בסדרי גודל יותר מאשר שבבים מסורתיים. זהו ללא ספק שבב הבינה המלאכותית שאינו GPU/CPU המצוטט ביותר בשוק – ראה https://stateof.ai/compute. . WSE-3 יחיד מספק 125 PetaFLOPS של מחשוב AI.

תמונה CS-3. The fastest AI accelerator :2 קרדיט: Cerebras System
בארכיטקטורת מחשוב העל ל AI של חברת Cerebras, מעבד WSE-3 מניע את מחשב ה CS-3 AI -, מערכת מחשוב בגובה 16 RU .חברת Cerebras יכולה להרחיב את ההיקף עד 2,048 מערכות CS3 ליצירת מחשבי-על רבי עוצמה ל AI , כאלה המסוגלים להגיע לביצועים של 256 אקסה-פלופס (ExaFLOPS) של חישוב AI כשהם מקושרים בצורה חלקה באמצעות התוכנה של Cerebras , כדי להתמודד בקלות עם עומסי העבודה המורכבים ביותר בתחום הבינה המלאכותית. מחשבי-על אלה תואמים באופן מלא למסגרות למידת מכונה סטנדרטיות בתעשייה, כמו PyTorch, מה שהופך אותם לנגישים וקלים לשילוב. אלפי מערכות CS נשלחו והותקנו ברחבי העולם. הטכנולוגיה של Cerebras Systems היא כיום הטכנולוגיה הבשלה היחידה מלבד מעבדי GPU שמסוגלת להריץ כל גודל של עבודות אימון והיסק (Inference) של מודלים בינה מלאכותית על אותה חומרה, ובקנה מידה גדול.
מחשבי-העל של Cerebras מפרידים בין זיכרון הדרוש לאחסון וטיפול במשקלים (Weights) לבין יכולת החישוב, מה שאומר שניתן להרחיב את הזיכרון ואת כוח החישוב בצורה בלתי תלויה – בניגוד למעבדי GPU. יתרה מזו, תפקידי הזיכרון עבור אימון AI מתבצעים באמצעות שרתי x86 רגילים, מה שהופך את הרחבת הזיכרון לזולה.
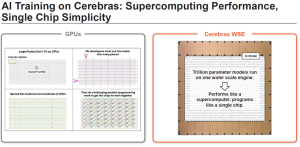
תמונה AI training on Cerebras: supercomputing performance of a :3 single machine, single chip simplicity for a cluster of machines קרדיט: Cerebras Systems
אבל היתרון העיקרי טמון בכך, שגם כאשר מאמנים את המודלים הגדולים ביותר עם טריליוני פרמטרים – ברמה של מודלים מתקדמים כמו של OpenAI ו-Anthropic – אין צורך לפצל את המודל לחלקים קטנים יותר כדי להתאים אותו לזיכרון המוגבל של אלפי יחידות GPU. במקום זאת, ניתן להשתמש בשיטת "מקבילות על בסיס נתונים" (Data Parallel), שבה המודל נשמר בשלמותו ורק נתוני האימון מפוזרים בצורה מקבילה בין מערכות הCS-3 הזמינות.
שיטה זו מובילה לסקיילינג ליניארי כמעט אידיאלי של מהירות האימון: הכפלת מספר מערכות CS-3 מקצרת את זמן האימון בחצי, שילוש מספר המערכות מקצר את זמן האימון לשליש, וכן הלאה.
למשל, בעבודה משותפת של Cerebras ו-Sandia National Laboratories, הראו כיצד ניתן לאמן מודל עם טריליון פרמטרים על מערכת CS-3 אחת בלבד. זה דרש רק 3% מהקוד הדרוש לעשות זאת עם GPU ורק 1% מהאנרגיה. נוסף על כך, כאשר נוספו מערכות CS-3 נוספות, הושגה האצה כמעט ליניארית: 16 מכונות השיגו מהירות אימון גבוהה פי 15.3.
ישנם יתרונות טכניים נוספים, כמו צריכת חשמל ושטח פיזי נמוכים ביחס לביצועים, פרוצדורות ניהול פשוטות יותר, מספר מצומצם של רכיבים, מה שמוביל גם לתחזוקה פשוטה יותר, ועוד.
מחשבי-העל של Cerebras "נפגשים" עם חוקרי בינה מלאכותית ועוסקים בלמידת מכונה ברמת PyTorch , מה שבז׳רגון התעשייתי אומר שהמשתמשים אינם צריכים להתעסק במורכבות של ארכיטקטורת המחשוב, או להשקיע זמן ואנרגיה בתכנון שיטות לחלוקת המודל בצורה מיטבית. אשכול של 2,048 מערכות CS-3 מתוכנת בדיוק כמו מכונה אחת של CS-3 , יש לשנות רק פרמטר קונפיגורציה יחיד. כך, המשתמשים יכולים להתמקד במה שבאמת יוצר ערך בפיתוח מודלי בינה מלאכותית – כלומר, בפיתוח המודל עצמו ובעבודה עם נתוני האימון, כדי להבטיח שהמודל האיכותי ביותר ייחשף לנתוני האימון המתאימים והעשירים ביותר.
ניתן לראות את היתרונות הללו ואת הפשטות הנובעת מהם גם בהקשר של "מפעל AI ציבורי" היפותטי – מקום שבו ארגונים מתעשיות ודיסציפלינות מדעיות שונות ירצו לאמן את המודלים שלהם עבור שימושים תעשייתיים או מדעיים. סביבה כזו שונה מאוד ממעבדות מדעי המחשב האקדמיות, שבהן מחקר מתמקד בהיבטים רבים של מדעי המחשב והמורכבות עצמה מהווה מנוע למחקר.
לגבי משתמשים מחוץ לעולם מדעי המחשב, מורכבות זו היא נטל ועלות שמעכבת את הדרך שלהם ליצירת ערך.
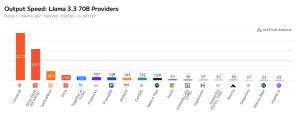
תמונה 70x speed unlocks AI voice, video, agents & reasoning :4 קרדיט: Cerebras System
ב"מפעל AI ציבורי" אין מקום רב להתעסקות מתמדת ולתכנות ברמות נמוכות. לכן, בעוד שמעבדי GPU הם הכרחיים לניסויים, ל-AI שאינו יוצר (Non-Generative AI) ולמחקר, הרי שבמונחים מעשיים, נוכחות של אשכולות Cerebras תאפשר מתן שירות פשוט וישיר לאימון מודלי AI .
עומס עבודה נוסף בתחום הבינה המלאכותית שאינו מתאים ל GPU הוא הרצת מודלי שפה גדולים (LLMs), כלומר ביצוע מה שנקרא הסקת מסקנות (inference) . אפשר לטעון שזהו תהליך חשוב אף יותר מאשר אימון המודל, שכן האימון הוא רק עלות, ואילו הערך העסקי האמיתי מופק מהשימוש במודלים.
הסקת מסקנות רלוונטית לכל תחום – עסקים, מגזר ציבורי ומדע. לדוגמה, חברת תרופות עשויה להריץ מודל LLM מותאם אישית לפי המידע הקנייני שלה כדי לסייע בכתיבת פטנטים ובכך לפנות את זמנם היקר של חוקרים. או סוכנות מודיעין עשויה לפרוס מודל LLM שמחבר בין דוחות טקסטואליים מהשטח לבין כמויות עצומות של תמונות לוויין, מה שמאפשר לאנליסטים לחקור מרחב מידע מגוון כדי לזהות אותות נדרשים. ניתן גם לדמיין מודל LLM בתחום מדע החומרים שמאיץ מחקר בפיתוח חומרים חדשים.
אופן הפעולה של הסקת מסקנות במודלי LLM הוא בכך שלא רק קלט הנתונים (טוקנים מהבקשה) משמש ליצירת הטוקן הבא, אלא שכל הטוקנים שנוצרו עד כה מוזנים חזרה אל תוך המודל בזמן בניית התגובה המלאה. משמעות הדבר היא שלכל טוקן חדש שנכנס, כל המודל חייב לעבור מהזיכרון המהיר (High Bandwith Memory) שעל ה GPU אל מודול החישוב באותו GPU דרך ערוץ מיוחד. בדור החדש ביותר של כרטיסי GPU תהליך הזה איטי פי יותר מ-2000 מאשר במעבד של Cerebras.
התוצאה היא תופעה שנקראת "קיר הHBM " – אף אחד ממודלי ה LLM שרצים על GPU לא יכול לבצע הסקת מסקנות במהירות העולה על כ 200 טוקנים לשנייה. לדוגמה, עבור מודל פופולרי של Meta – Llama 3.3 עם 70 מיליארד פרמטרים – גם ענני GPU האופטימליים ביותר לא מצליחים לעבור מהירות של 200 טוקנים לשנייה, כאשר עננים נפוצים מגיעים לפחות מ-60 טוקנים לשנייה. לעומת זאת Cerebras מגיע למהירות של 2400 טוקנים לשנייה, עם הזמן המהיר ביותר לטוקן ראשון – לפחות 30% מהר יותר מהענן המהיר ביותר מבוסס GPU וחצי מהזמן של Llama 3.3 70b שרץ על ענן כזה.
למה הסקת מסקנות מהירה חשובה כל כך? לא רק שהיא מאפשרת חוויית משתמש מדהימה – תשובות מיידיות , אלא שהיא גם מאפשרת ביצוע תהליכי הסקה מורכבים (ריבוי שלבי הסקה לכל בקשה), הופכת סוכנים חכמים (AI agents) לפרקטיים – כאשר כל בקשה יוצרת שרשרת של הסקות – ומאפשרת תקשורת בזמן אמת, למשל קולית, הרגישה מאוד לעיכובים. דוגמאות אלו מדגימות כיצד הסקת מסקנות מהירה מרחיבה את גבולות היישום של בינה מלאכותית גנרטיבית.
לסיכום, אנו רואים כיצד עומסי העבודה החדשים של הבינה המלאכותית הגנרטיבית מכבידים על ה-GPU ביישומים פרקטיים, בדומה לאופן שבו רשתות נוירונים בתחילת דרכן הכבידו על המעבדים (CPU) לאחר שאלו הוכתרו ל"מלכי החישוב" . Cerebras פיתחה טכנולוגיה זמינה ומוכחת לשימוש נרחב שמאפשרת אימון והרצה של מודלי LLM לכל יישום מעשי – במהירויות ובפשטות שה GPU אינו מסוגל להשיג. בעת תכנון כזה או אחר לתמיכה בהרצת מודלים של בינה מלאכותית או יישום ארגוני של בינה מלאכותית גנרטיבית, חשוב לקחת בחשבון את בעלי העניין, את הערך שהם מחפשים ואיך ניתן להפיק תועלת מהאפשרויות הרחבות ביותר.
Cerebras מספקת את הפתרונות הנדרשים למענה על נקודות אלו.
מקור הכתבה הוא מחברת Cerebras, שוכתבה באדיבות חברת ניסקו, שותפתה של Cerebras בישראל.
לפרטים נוספים ניתן לפנות למיקי קליין, miki@nisko.co.il, 054-5550750




