




 לעד שיינר, סמנכ"ל השיווק של חברת מלאנוקס טכנולוגיות שימש במספר תפקידי ניהול מאז הצטרפותו למלאנוקס. בתפקידו האחרון שימש שיינר כסמנכ"ל פיתוח שווקים. שיינר הצטרף למלאנוקס ב-2001 כמהנדס פיתוח ואחר כך ניהל והוביל את פיתוחם של מספר מוצרי חומרה ותוכנה. בהמשך, שימש שיינר במספר תפקידי ניהול בכירים בתחום השיווק. הוא בוגר תואר ראשון ושני בהנדסת חשמל מהטכניון והוא מחזיק במספר פטנטים בתחום רשתות תקשורת מהירות ותרם לפיתוחם של תקניPCISIG: ה-PCI-X וה-PCIe. שיינר היה ממקימי הועדה המייעצת למחשוב על (HPC Advisory Council) ומכהן כיושב ראשה משנת 2008.
לעד שיינר, סמנכ"ל השיווק של חברת מלאנוקס טכנולוגיות שימש במספר תפקידי ניהול מאז הצטרפותו למלאנוקס. בתפקידו האחרון שימש שיינר כסמנכ"ל פיתוח שווקים. שיינר הצטרף למלאנוקס ב-2001 כמהנדס פיתוח ואחר כך ניהל והוביל את פיתוחם של מספר מוצרי חומרה ותוכנה. בהמשך, שימש שיינר במספר תפקידי ניהול בכירים בתחום השיווק. הוא בוגר תואר ראשון ושני בהנדסת חשמל מהטכניון והוא מחזיק במספר פטנטים בתחום רשתות תקשורת מהירות ותרם לפיתוחם של תקניPCISIG: ה-PCI-X וה-PCIe. שיינר היה ממקימי הועדה המייעצת למחשוב על (HPC Advisory Council) ומכהן כיושב ראשה משנת 2008.
שאלתי את שיינר האם ישנן התפתחויות חשובות בתחום הקישוריות למחשוב עתיר הביצועים, מעבר אולי למוצרי רשת המספקים רוחב פס גדול יותר? והוא ענה: "המהפכה האחרונה בתחום המחשוב עתיר הביצועים (HPC) היא המעבר לארכיטקטורת עיצוב משותף (Co Design) – קיום שיתוף פעולה בין גורמים משפיעים בתעשייה, אנשי אקדמיה ויצרנים כדי להגיע לביצועים ברמת אקסה (Exascale), באמצעות שימוש בגישה הוליסטית ברמת המערכת להשגת שיפורי ביצועים משמעותיים. ארכיטקטורת העיצוב המשותף מנצלת את יעילות המערכת ומשיגה ביצועים אופטימליים על ידי יצירת סינרגיות בין החומרה והתוכנה וגם בין רכיבי החומרה השונים בתוך מרכז הנתונים.
כיום קיימת בתעשייה הסכמה על כך שהמעבד הגיע לגבול יכולת הסקלאביליות שלו, מה שיצר צורך ברשת חכמה שתפעל כ-"מעבד משותף" (co-processor) ותחלק את האחריות לטיפול בעומסי העבודה ובהאצתם. באמצעות מיקום חישובי אלגוריתמים הקשורים לנתונים בתוך רשת חכמה, ניתן לשפר באופן דרמטי את ביצועיהם של מרכזי הנתונים ושל היישומים, ואת יכולת הסקלאביליות שלהם."
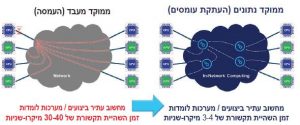
תרשים 1 – ארכיטקטורה ממוקדת-נתונים: מעבר מארכיטקטורה ממוקדת-מעבד
לממוקדת-נתונים לצורך התגברות על צווארי הבקבוק של השהיית תקשורת רשת
מוצרי מלאנוקס מבוססים על טכנולוגיית ה-RDMA, באמצעותה יכול כרטיס הרשת, תחת בקרת היישום הרץ על השרת, לנתב נתונים ישירות אל או החוצה מזיכרון היישום (השרת) תוך עקיפת מערכת ההפעלה. לשאלתי – האם המעבר ל- Co Design דורש מאפיינים מעבר למה שהציעו מוצרי מלאנוקס באופן מסורתי עד כה? ענה שיינר: "הדור החדש של פתרונות קישוריות חכמה מבוסס על ארכיטקטורה ממוקדת-נתונים, שיכולה להעתיק את העומסים (offload) של כל פונקציות הרשת מהמעבדים לרשת (ו-RDMA הוא ביסוד העתקת עומסים זו), אבל בנוסף – וכאן החידוש – לבצע חישובים תוך כדי מעבר הנתונים. בכך מחזורי מעבדים מתפנים, ומגבירים את יעילות המערכת. בעזרת ארכיטקטורה חדשה זו, הקישוריות תומכת בניהול וביצוע של אלגוריתמים נוספים בתוך הרשת, מה שמאפשר למשתמשים להריץ אלגוריתמים על הנתונים בזמן שהם מועברים דרך קישוריות המערכת, במקום לחכות עד להגעת הנתונים למעבדים. פתרונות קישוריות חכמה יכולים כעת לספק גם חישוביות וגם זיכרון פנים-רשתיים, והם מייצגים את הגישה המתקדמת ביותר בתעשייה להשגת ביצועים וסקלאביליות עבור אשכולות מחשוב עתירי ביצועים."
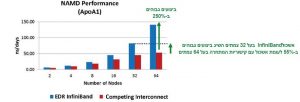
תרשים 2 – השוואת ביצועים של InfiniBand לעומת קישוריות מתחרה בהרצת NAM
כאשר שאלתי – כיצד מותאמת יכולת המחשוב הפנים-רשתית לעבודה בתחומי HPC, עם ספריות MPI לחישובים מקביליים למשל? שיינר ענה: "טכנולוגיות האצה מבוססות חומרה של מלאנוקס טכנולוגיות, כגון SHARP (Scalable Hierarchical Aggregation and Reduction Protocol), משמשות להעתקת עומסים של פרוטוקולי רדוקציה ואגרגציה של נתונים, להתאמה מבוססת-חומרה של תגי MPI ולהעתקת עומסים של MPI Rendezvous. טכנולוגיות אלה הן רק חלק מהפתרונות שפועלים במשולב כדי להביא להעתקת עומסים משמעותית של מחשוב הקשור לתקשורת בין-תהליכים, ובכך לאפשר לאלגוריתמים לעבד נתונים תוך כדי תנועה. ארכיטקטורה ממוקדת-נתונים העושה שימוש בטכנולוגיות מלאנוקס יכולה לספק יתרונות משמעותיים בביצועים ובסקלאביליות על
ארכיטקטורה ממוקדת-מעבד." ולגבי יתרונות הארכיטקטורה הממוקדת נתונים המשלבת פתרונות קישוריות של מלאנוקס התומכים ב- Co-Design? פירט שיינר: "יתרונות פתרונות הקישוריות של מלאנוקס מבחינת ביצועים וסקלאביליות על פני פתרונות מתחרים הודגמו בשימוש במגוון יישומים. באתרים שונים נערכו בדיקות על מערכות ייצור, המשוות בין אשכול שרתים InfiniBand EDR (בקצב 100 גיגה-ביט לשנייה) לאשכול מקושר עם טכנולוגיה מתחרה. אשכול InfiniBand כלל שרתים כפולי תושבת (dual-socket) ומעבדי Intel Xeon 16-core E5-2697 v4 במהירות 2.60 גיגה-הרץ. אשכול הקישוריות המתחרה כלל שרתים כפולי תושבת עם מעבדי Intel Xeon 18-core Intel E5-2697 v4 במהירות 2.30 גיגה-הרץ. למרות שקיים הבדל קטן בין תדרי המעבדים, ניתן בהחלט להשוות את ביצועי הסקלאביליות של שני האשכולות. כפי ששני מקרי המבחן הבאים מראים בבירור, תשתית InfiniBand מציעה ביצועים גבוהים באופן דרמטי ומורידה את עלות הבעלות הכוללת."
מקרה מבחן: NAMD
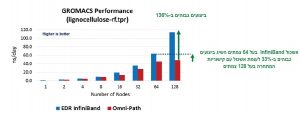
תרשים 3 – השוואת ביצועים של InfiniBand לעומת קישוריות המתחרה בהרצת GROMACS
NAMD הוא יישום של דינמיקה מולקולרית לכימיה וביולוגיה כימית. תרשים 2 להלן מציג תוצאות בדיקה עבור בוחן הביצועים הסטנדרטי ApoA1 של NAMD. כפי שניתן לראות, אשכול InfiniBand בעל 64 צמתים השיג ביצועים מרשימים הגבוהים ב- 250% לעומת אשכול עם קישוריות המתחרה בעל 64 צמתים. יתר על כן, בהרצת אותו בוחן ביצועים על אשכול InfiniBand בעל מחצית ממספר השרתים (32 צמתים), הוא עדיין השיג ביצועים גבוהים ב-55% לעומת האשכול עם קישוריות המתחרה בעל 64 הצמתים.
מקרה מבחן : GROMACS
GROMACS היא חבילת דינמיקה מולקולרית המשמשת לסימולציות של חלבונים, שומנים וחומצות גרעין.
תרשים 3 מציג תוצאות בדיקה עבור בוחן ביצועים סטנדרטי של סימולציית lignocellulose. כפי שניתן לראות, אשכול InfiniBand בעל 128 צמתים השיג ביצועים גבוהים ב- 136% לעומת אשכול עם קישוריות המתחרה בעל 128 צמתים. יתר על כן, בהרצת אותו בוחן ביצועים על אשכול InfiniBand בעל מחצית ממספר השרתים (64 צמתים), הוא עדיין השיג ביצועים גבוהים ב- 33% לעומת האשכול עם קישוריות המתחרה בעל 128 הצמתים.
לסיכום התוצאות ביחד
שיינר מסביר: "שני היישומים דורשים תקשורת בין-תהליכים מהירה ויעילה. היכולת של InfiniBand להפעיל חלק גדול משכבת התקשורת של MPI בתוך הרשת מגבירה מאוד את הביצועים ואת הסקלאביליות שניתן להשיג באמצעות התשתית של מחשוב עתיר ביצועים. בשני מקרי המבחן, InfiniBand סיפקה ביצועים גבוהים יותר (250% יותר במקרה של NAMD, ו-136% במקרה של GROMACS) לעומת קישוריות המתחרה – עבור עבודה על אשכול בגודל זהה. לא פחות חשוב מכך, בשני המקרים InfiniBand השיגה ביצועים גבוהים יותר גם עם מחצית ממספר השרתים (NAMD, אשכול InfiniBand בעל 32 צמתים השיג ביצועים גבוהים ב-55% לעומת אשכול עם קישוריות המתחרה בעל 64 צמתים; עבור GROMACS אשכול InfiniBand בעל 64 צמתים השיג ביצועים גבוהים ב-33% לעומת אשכול עם קישוריות המתחרה בעל 128 צמתים)."
