




רכיבי FPGA מציעים את יכולת הגדרת הקונפיגורציה הדרושה להסקת מסקנות בתהליך לימוד מכונה בזמן אמת, עם גמישות ההתאמה לעומסי העבודה של העתיד. אפשרות הגישה ליתרונות אלו שתינתן לחוקרי נתונים ולאנשי פיתוח, מזמינה כלים שיהיו מקיפים וקלים לשימוש.
מבוא: הסקת מסקנות בתהליך לימוד מכונה בזמן אמת
לימוד מכונה הוא הכוח שמאחורי שירותים חדשים שמשפרים את האינטראקציה שבין קול טבעי לזיהוי תמונה, על מנת לספק חוויות של מדיה חברתית או של מרכז תקשורת, שמתנהלות באופן חלק. יתר על כן, היכולת של רשתות עצביות מלאכותיות, המאומנות בלמידה עמוקה (deep learning), לזהות תבניות או חריגות בכמויות עצומות של נתונים הקשורים למספרים גדולים של משתנים, משנה גם את הדרך שבה אנו מתנהלים במחקר מדעי, תכנון פיננסי, ניהול ערים חכמות, תכנות רובוטים תעשייתיים ובתהליכי אספקת טרנספורמציה עסקית ספרתית (digital business transformation), באמצעות שירותים כגון תאומים ספרתיים (digital twin) ותחזוקה חזויה.
בין אם הרשתות המאומנות פרושות לצורך הסקת מסקנות בענן או במערכות משובצות בקצוות הרשת, רוב הציפיות של המשתמשים מבקשות קצב העברת נתונים דטרמיניסטי וזמן אחזור (latency) קצר. לקבלת שתי תוצאות אלו בו זמנית, בתוך מארז בגודל סביר ותחת מגבלות הספק, יש צורך במנוע מחשב יעיל ומקבילי במידה רבה, שיימצא בלב המערכת שתוכננה להעביר נתונים בצורה יעילה פנימה והחוצה. להשגת אלו נדרשות תכונות כגון, היררכית זיכרון גמישה וחיבורי ביניים על פני רוחב פס רחב ניתן להתאמה.
בניגוד לדרישות אלו, המנועים מבוססי מעבדי GPU, המשמשים בדרך כלל לצורך אימון רשתות עצביות מלאכותיות – אשר צורכים זמן ומשאבי tera FLOPS רבים של מחזורי מחשוב – יש מבנים קשיחים של חיבורים פנימיים והיררכית זיכרון שאינם מתאימים כל כך להסקת מסקנות בזמן אמת. בעיות כגון שכפול נתונים, השמטות של זיכרון מטמון וחסימות, מתרחשות באופן נפוץ. על מנת להשיג ביצועים משביעי רצון בהסקת מסקנות, יש צורך בארכיטקטורה גמישה יותר שניתנת לשדרוג.
פרוייקטים מובילים משפרים את יכולת הגדרת קונפיגורציה
רכיבי FPGA (מערכי שערים ניתנים לתכנות בשטח), אשר משלבים אריחי מחשוב (compute tiles) שעברו אופטימיזציה, זיכרון מקומי מבוזר וחיבורים פנימיים משותפים ללא חסימה וניתנים להתאמה, יכולים להתגבר על מגבלות מסורתיות של אבטחת תפוקה דטרמיניסטית וזמן אחזור קצר. אכן, ככל שעומסי העבודה של לימוד מכונה הופכים להיות תובעניים יותר, פרוייקטים פורצי דרך של לימוד מכונה, כגון Project Brain Wave של Microsoft משתמשים ברכיבי FPGA לביצוע חישובי זמן אמת באופן שהוא כדאי מבחינת עלותו ובזמן אחזור נמוך במידה קיצונית, שהוכח שאין אפשרות לממש אותו, בעזרת יחידות GPU.
פרוייקט מתקדם נוסף של לימוד מכונה, מאת ספק שירותי מחשב גלובליים Alibaba Cloud, בחר ברכיבי FPGA כבבסיס לבניית מעבד DLP ('מעבד ללמידה עמוקה' – Deep Learning Processor – DLP) עבור זיהוי וניתוח של תמונות. רכיבי FPGA איפשרו למעבד DLP לקבל בו זמנית זמן אחזור נמוך וביצועים גבוהים, אשר 'קבוצת שירותי התשתית' של החברה שיערה שלא יכולה הייתה לממש בעזרת שימוש ביחידות GPU. באיור 1 אפשר לראות את התוצאות מהניתוח שערך הצוות עם רשת שיורית (residual network) עמוקה – ResNet-18 – שמראה כיצד מעבד DLP מבוסס רכיבי FPGA משיג זמן אחזור של רק 0.174 שניות: מהיר יותר ב- 86% מהמקרה של מעבד GPU שווה ערך. תפוקה שנמדדה בשאילתות לשנייה (Queries Per Second – QPS) גבוהה יותר מאשר פי שבעה.
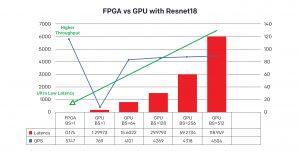
איור 1. השוואה בין הביצועים וזמן האחזור של מעבד DLP של Alibaba Cloud.
פרוייקטים כגון Brain Wave של Microsoft ומעבד DLP של Alibaba הקימו בהצלחה ארכיטקטורות חומרה חדשות שיש להן יכולת להאיץ את עומסי העבודה של בינה מלאכותית (AI). זו רק תחילתו של המסע, שבסופו של דבר יהפוך את האצת לימוד המכונה לזמינה באופן נרחב ללקוחות בשירותי ענן, וכן למשתמשים תעשייתיים ולקהיליית תעשיית כלי הרכב, אשר לעתים קרובות יותר מחפשים לפרוש הסקת מסקנות בלימוד מכונה במערכות משובצות בקצות הרשת.
מאידך, כמה ספקי שירות מעונינים ליצוק את לימוד המכונה אל תוך מערכות קיימות על מנת להרחיב ולהאיץ את תרחישי השימוש שהוקמו. דוגמאות כוללות אבטחת רשתות, שבהן לימוד מכונה משפר את הכרת התבנית כדי להניע גילוי מהיר יותר של תוכנה זדונית וחריגות מסוכנות. הזדמנויות אחרות כוללות שימוש ביישומי לימוד מכונה, כגון זיהוי פנים או גילוי הפרעות אשר עוזרים להפעיל ערים חכמות באופן חלק יותר.
האצת בינה מלאכותית עבור מי שאינם מומחים ברכיבי FPGA
חברת Xlinix הקימה מערכת אקולוגית של משאבים שמאפשרת למשתמשים לנצל את הפוטנציאל הטמון ברכיבי FPGA להאצת עומסי עבודה של בינה מלאכותית בענן או בקצות הרשת.
בין הכלים הזמינים, קיימת הסוויטה ML-Suite (איור 2) אשר מטפלת בהידור הרשת העצבית המלאכותית, כדי שתפעל בחומרה של רכיבי FPGA של Xilinix. היא יכולה לפעול עם רשתות עצביות מלאכותיות שנוצרו במסגרות עבודה משותפות של לימוד מכונה, בהן נכללות TensorFlow, Caffe, MxNet ואחרות. ממשק Pyton API מקל על הפעילות האינטראקטיבית עם הסוויטה ML-Suite.

איור 2. ML-Suite של Xlinix מספקת מערכת אקולוגית של משאבים לפיתוח לימוד מכונה.
מאחר שמסגרות עבודה של לימוד מכונה נוטות ליצור רשתות עצביות מלאכותיות מבוססות על אריתמטיקה של נקודה צפה ב- 32 סיביות, הסוויטה ML-Suite כוללת כלי כימוי (Quantizer) שממיר את האריתמטיקה לשווה הערך בנקודה קבועה, אשר מתאים בצורה טובה יותר למימוש ברכיבי FPGA. כלי הכימוי הוא חלק ממערך של תוכנת ביניים (middleware), כלים להידור ולאופטימיזציה, וזמן הפעלה, שנקרא באופן כולל xfDNN, אשר מבטיח שהרשת העצבית המלאכותית תספק את הביצועים הטובים ביותר האפשריים ברכיבי סיליקון FPGA.
המערכת האקולוגית גם ממנפת את הרכישה של DeePhi Technology שביצעה על ידי Xlinix באמצעות שימוש בגוזם (pruner) של DeePhi כדי להסיר משקלים קרובים לאפס (near zero weight) ולדחוס ולפשט את שכבות הרשת. הגוזם של DeePhi הוכיח עצמו כמגדיל את מהירות הרשת העצבית המלאכותית פי עשרה ומקטין באופן משמעותי את צריכת ההספק של המערכת, מבלי לגרום נזק לביצועים הכוללים ולדיוק.
כאשר הדברים מגיעים לפרישה של הרשת העצבית המלאכותית שעברה המרה, הסוויטה ML-Suite מספקת שכבות של מעבד xDNN מותאמים אישית, שמנעו מאנשי התכנון את המורכבות הכרוכה בתכנון רכיבי FPGA ונצלו את המשאבים שעל השבב באופן יעיל. כל שכבה קיימת בדרך כלל עם קבוצת הפקודות המותאמת אישית שלה, לצורך הפעלה של סוגים שונים של רשתות עצביות מלאכותיות. המשתמשים יכולים לפעול יחד עם הרשת העצבית המלאכותית באמצעות ממשקי RESTful API, תוך כדי עבודה בתוך הסביבה המועדפת עליהם.
עבור פרישות שנערכות בחצרים, כרטיסי המאיצים AlveoTM של Xlinix מסירים את האתגרים הכרוכים בפיתוח חומרה ומפשטים את הטמעת לימוד המכונה בעזרת יישומים שקיימים במרכז הנתונים.
המערכת האקולוגית תומכת בפרישת לימוד מכונה בתרחישי שימוש משובצים או בתרחישי שימוש קצה, כשהיא ממנפת לא רק את הגוזם, אלא גם כלי כימוי, מהדר וזמן הפעלה של DeePhi Technology, על מנת ליצור רשתות עצביות מלאכותיות יעילות לביצועים גבוהים, שמתאימות לחומרה משובצת מוגבלת במשאבים (איור 3). חומרה מוכנה לשימוש כגון הכרטיס Zynq™ UltraScale™ 9 והמערכת על המודול Zynq 7020מפשטת את פיתוח החומרה ומאיצה את האינטגרציה של התוכנה.

איור 3. הסוויטה ML-Suite מספקת כלים שעברו אופטימיזציה עבור לימוד מכונה בענן ולימוד מכונה בקצה/משובץ
קיימים גם מספר ספקי תוכנה חדשניים בלתי תלויים שבנו שכבות של הסקת מסקנות ברשת עצבית מלאכותית בקונבולוציה (CNN) שניתן לפרוש אותן לרכיבי FPGA.
Mipsolosgy בנתה את Zebra, מאיץ הסקת מסקנות CNN שיכול בקלות להחליף מעבד CPU או מעבד GPU והוא תומך במספר רשתות סטנדרטיות (למשל, Resent50, InceptionV3, Caffenet) ובמסגרות עבודה מותאמות אישית, אשר הציג תפוקה מדהימה בזמן אחזור נמוך ביותר, כמו למשל, Resent50 ב-3,700 תמונות בשנייה.
מעבד DPU של Omnitek הוא דוגמה נוספת לשכבת הסקת מסקנות שמפעילה ביצועים גבוהים מאוד של מעבד DNN על רכיבי FPGA. למשל, ברשת GoogLeNet Inception-v1 CNN המעבד של Omnitek מבצע הסקת מסקנות על תמונות 224×224 בעזרת עיבוד של מספרים שלמים בני 8 סיביות, ביותר מאשר 5,300 פעולות של הסקת מסקנות בשנייה על כרטיס המאיץ במרכז הנתונים Alveo של Xlinix.
מחשוב ניתן לקונפיגורציה מחדש עבור גמישות בעתיד
בנוסף לאתגרים הקשורים בהבטחת הביצועים הנדרשים של הסקת מסקנות, אנשי הפיתוח שפורשים לימוד מכונה חייבים גם לקחת בחשבון שהנוף הטכנולוגי הכולל שמקיף את לימוד המכונה ואת הבינה המלאכותית משתנה במהירות. את הרשתות העצביות המלאכותיות מהשורה הראשונה הקיימות היום, אפשר בקלות להחליף ברשתות חדשות ומהירות יותר, שאולי לא יהיו מתאימות בצורה טובה לארכיטקטורות חומרה מסורתיות.
לעת עתה, יישומים מסחריים של לימוד מכונה נוטים להתמקד בטיפול בתמונה ובהכרת עצמים או מאפיינים, שמטופלים בצורה הטובה ביותר בעזרת רשתות עצביות קונבולוציונליות. גישה זו יכולה להשתנות בעתיד כאשר אנשי התכנון ימנפו את עוצמת לימוד המכונה על מנת להאיץ ביצוע משימות כגון מיון דרך מחרוזות או ניתוח נתונים שאינם מחוברים. הדרך הטובה יותר לשרת עומסי עבודה כגון אלו, היא על ידי סוגים אחרים של רשתות עצביות מלאכותיות כגון רשת 'יער אקראי' (random forest) או רשת זיכרון לטווח ארוך קצר (LSTM). אם יהיה צורך לעדכן את החומרה כדי לארח סוגים שונים של רשתות עצביות מלאכותיות שנדרשות כדי להבטיח זמני מיחשוב מהירים עם זמן אחזור קצר, הדבר יכול לקחת חודשים או שנים.
בניית מנוע הסקת מסקנות מבוסס על מעבדים כגון מעבדי GPU או רכיבי ASIC מותאמים אישית, שיש להם ארכיטקטורה קבועה, אינה משאירה דרך קלה או דרך פשוטה לעדכון החומרה. הקצב של פיתוח בינה מלאכותית עולה כיום על זה של סיליקון, ולכן רכיב ASIC מותאם אישית שיכול לייצג את הדגם שבחוד החנית בתחילת שלב הפיתוח שלו, יהיה לא מעודכן כבר בטרם יהיה מוכן לפרישה בשטח.
לעומת זאת, יכולת הגדרת הקונפיגורציה החוזרת של רכיבי FPGA והגמישות לביצוע התאמה אישית של המשאבים, מהוות חוזקות עיקריות שמאפשרות להתקנים אלו לעמוד בקצב עם ההתפתחות של תחום מפעים זה. אנו כבר יודעים שרכיבי FPGA מתאימים היטב לקיבוץ אשכולות (clustering) בעלי זמן אחזור קצר שמשמש ללימוד שאינו בפיקוח, שהוא ענף אחר שמתפתח בתחום הבינה המלאכותית ומתאים במיוחד בצורה טובה למשימות כגון ניתוחים סטטיסטיים.
שימוש בכלים כגון הסוויטה ML-Suite על מנת לשפר ולהדר את הרשת לצורך פרישת רכיבי FPGA מאפשרת לאנשי הפיתוח לעבוד ברמה גבוהה בסביבה האישית שלהם מבלי שיצטרכו שתהיה להם מומחיות ברכיבי FPGA שתכוון את ההחלטות של המהדר, תוך כדי שהם משמרים את הגמישות להגדרת הקונפיגורציה של החומרה בעתיד, על מנת לתמוך בדורות העתידיים של רשתות עצביות מלאכותיות.
מסקנות
רכיבי FPGA ידועים כמי שמספקים את האצת הביצועים והגמישות לעתיד שנדרשים לכל מי שעוסק בתחום לימוד מכונה. לא רק כדי לבנות מנועים להסקת מסקנות בעלי ביצועים גבוהים ויעילים, לצורך פרישה מיידית, אלא גם כדי להתאים עצמם לשינויים המהירים, הן בדרישות הטכנולוגיה והן בדרישות השוק לצורך לימוד מכונה. האתגר הוא להפוך את היתרונות הארכיטקטוניים של רכיבי FPGA לנגישים למומחי לימוד מכונה ובאותו זמן לעזור ולהבטיח את הביצועים הטובים ביותר ואת המימוש היעיל ביותר. המערכת האקולוגית של Xlinix משלבת כלי FPGA מהשורה הראשונה עם ממשקי API נוחים, על מנת לאפשר לאנשי הפיתוח לנצל את מלוא היתרונות של הסיליקון מבלי שיהיה צריך ללמוד את הנקודות העדינות של תכנון ברכיבי FPGA.
