




"ארכיטקטורת האינפיניבנד עושה שימוש במנועי התרת עומסים בחומרה, המסייע להפחתת נצילות המעבד ולהאצת ניתוח נתונים. כתוצאה מכך, ביצועי היישומים גבוהים יותר וכך גם ההחזר הכולל על ההשקעה. אינפיניבנד היא טכנולוגיית הקישוריות המובילה של ימינו עבור פלטפורמות מחשוב ואחסון עתירות ביצועים."
(גלעד שיינר)
בחירת הקישוריות הנכונה עבור פלטפורמות מחשוב ואחסון עתירות ביצועים, היא קריטית לניצול מירבי של המערכת והחזר מירבי על השקעה. כיום, טכנולוגיית הקישוריות הפכה לקריטית מאי פעם, בשל מספר גורמים:
הצמיחה האקספוננציאלית בכמויות הנתונים שאנו אוספים והנתונים בהם אנו משתמשים
הצורך לנתח נתונים בזמן אמת
העלייה ברמת המורכבות של מודלים לסימולציות מחקר והנדסה
העלייה ברמת הביצוע המקבילי של אלמנטי מחשוב

גלעד שיינר סמנכ"ל השיווק, מלאנוקס
במרוצת הזמן, טכנולוגיות הקישוריות נעשו מתוחכמות יותר, והן טומנות בחובן יכולות חכמות יותר (כמו מנועי התרת עומסים – offload engines), המאפשרות לקישוריות לעשות יותר מאשר להעביר נתונים בלבד. קישוריות חכמה יכולה להגדיל את יעילות המערכת; קישוריות עם מנועי התרת עומסים (קישוריות של offload) מפחיתה באופן דרמטי את תקורת המעבד, ומאפשרת הקדשת יותר מחזורי מעבד ליישומים. מחזורי המעבד הנוספים מאפשרים, בתורם, ביצועי יישומים ופרודוקטיביות משתמש גבוהים יותר.
בעולם האית'רנט (Ethernet), היינו עדים לפיתוח מספר רב של טכנולוגיות stateless offloads (כלומר, התרת עומסים ללא שמירת מידע אודות מצב או קלט קודם). כך, שלא קיים בימינו בקר אית'רנט שאינו תומך בהתרות עומסים אלה. החברות Myricom Myrinet ו-Quadrics QsNet, התמקדו באפשור מנועי התרת עומסים חכמים. ניתן לטעון ששתיהן איבדו את נתחי השוק שלהן כי הטכנולוגיות שהציגו היו קנייניות. Cray Aries, IBM BlueGene ואינפיניבנד (InfiniBand), גם הן דוגמאות לטכנולוגיות קישוריות מסוג offload; מבּיניהן, אינפיניבד היא טכנולוגיה סטנדרטית בתעשייה, וככזו, תורמת לייצוב מעמדה של קישוריות מסוג offload כמובילה בשוק.
ההשפעה של אימוץ קישוריות ה-offload ניכרת בהרבה מעבר לתחום המחשוב עתיר הביצועים. לדוגמה, מיקרוסופט דיווחה בוועידת ה-Open Networking Summit, כי טכנולוגיית ה-Remote Direct Memory Access, או ה-RDMA, באמצעותה כרטיס הרשת יכול לנתב נתונים ישירות לתוך זיכרון או מחוץ לזיכרון היישום/השרת תוך עקיפת מערכת ההפעלה, מאפשרת העברת נתונים עם אפס תקורה למעבד. לכן, הפכה החברה את השימוש בטכנולוגיה זו לסטנדרט עבור פלטפורמת הענן שלה.
קיימת טכנולוגיית קישוריות אחת למרכזי נתונים שאינה כוללת יכולות offload. טכנולוגיה זו הוצגה לראשונה על ידי חברת PathScale במוצר InfiniPath, ונרכשה בהמשך על ידי QLogic, ששינתה את שם הטכנולוגיה ל-TrueScale. לפני ארבע שנים, אינטל רכשה את אותה הטכנולוגיה ושינתה את שמה שוב, הפעם ל-OmniPath (בדומה לשם המקורי).
כהצדקה לפיתוח קישוריות רק בטכנולוגיית onload, בה משימות העברת נתונים ברשת מנוהלות על ידי המעבד, טענה PathScale שעם הופעת מעבדים מרובי ליבות, בהן המשתמש אינו מסוגל להשתמש בכולן, ניתן להקצות חלק מהליבות לפעילות הרשת. לטענה זו אין תוקף בפועל, מפני שהדרישה לריבוי ליבות נבעה במקור מהצורך להגדיל את יכולות המחשוב של המערכת. גישת ה-onload זכתה לאימוץ מוגבל ביותר, משום שהיא מפחיתה את יעילות המעבד ואת ביצועי היישום הכלליים, במקום לשפר אותם. עבור אינטל, לעומת זאת, לאימוץ טכנולוגיה זו היגיון עסקי מושלם – זה יכול לסייע במכירת יותר מעבדי אינטל.
-

- איור 1. פרסום אינטל המשווה נצילות מעבד בין OmniPath לבין אינפיניבנד
-
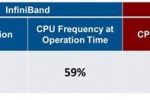
- איור 2. השוואת נצילות מעבד מפרסום מלאנוקס "Offloading vs. Onloading: The Case of CPU Utilization"
-

- איור 3. מצגת אינטל על OmniPath, אוקטובר 2016, המגדירה את השוואת נצילות המעבד במאמר "Offloading vs. Onloading: The Case of CPU Utilization", כ-FUD
-

- איור 4. מצגת OmniPath של אינטל, אוקטובר 2016, מצהירה כי טענות העבר לגבי ביצועיו הנמוכים של היישום (Quantum Espresso) הן בגדר הפצת מידע שגוי
-
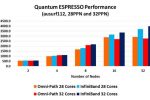
- איור 5. ביצועי יישום Quantum ESPRESSO: השוואה מעודכנת בין אינפיניבנד ל-OmniPathבתגובה למצגת של אינטל מאוקטובר 2016, שהגדירה את הטענות לגבי ביצועי היישומים בטכנולוגיה שלה כ-"FUD", הפצת מידע שגוי
בכנס HPC China באוקטובר 2016, הציגה אינטל השוואת ביצועים בין OmniPath לבין אינפיניבנד, במסגרתה בחנה את נצילות המעבד במהלך בדיקה להעברת נתונים. ניתן היה לצפות כי טכנולוגיית offload כגון אינפיניבנד, אשר אמורה, על פי הדיווחים, להפיק "כמעט אפס תקורת מעבד", תפגין נצילות מעבד נמוכה יותר לעומת טכנולוגיית onload של OmniPath, אבל דו"ח אינטל טען, באופן מפתיע, את ההפך הגמור. ראו איור 1.
על פי תוצאות הבדיקה של אינטל, טכנולוגיית OmniPath צורכת 65% ממחזורי המעבד כדי להעביר את הנתונים, בעוד טכנולוגיית אינפיניבנד צורכת 100%, או את כל מחזורי המעבד. ודאי נתקשה להאמין, אך אינטל אף הגדירה את מאמרה של מלאנוקס, "Offloading vs. Onloading: The Case of CPU Utilization" שפורסם ב-HPC Wire, כ-"FUD" או "Fear, Uncertainty and Doubt" ("פחד, אי ודאות וספק"). מאמרה של מלאנוקס הציג מקרה המתאר כיצד ראוי למדוד ולהשוות נצילות מעבד מעל OmniPath ומעל אינפיניבנד. תחת המתודולוגיה הזו, מלאנוקס מצאה כי OmniPath דרשה 60% נצילות מעבד, בעוד אינפיניבנד דרשה 0.8% בלבד. מעניין לציין כי מאמרה של מלאנוקס והדיווח מטעם אינטל נקבו בערך באותה רמת נצילות מעבד מעל OmniPath (מלאנוקס טענה 59.5% ואינטל טענה 65%), ובכל זאת ישנו הבדל עצום בטענות לנצילות המעבד מעל אינפיניבנד (0.8% לעומת 100%). איור 2להלן מציג טבלה עם התוצאות מהפרסום של מלאנוקס, ואילו איור 3 מראה את תיוג אינטל לנתונים של מלאנוקס כ-"FUD".
השאלה המתבקשת היא, כיצד אינטל טוענת שמדדה 100% נצילות מעבד מעל אינפיניבנד, בעוד שכל שאר החברות שדיווחו תוצאות ביצועים עבור אינפיניבנד טענו נצילות בשיעור של כמעט 0%, כולל אינטל במאמר קודם. ראו, למשל: "Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store", מאת Christopher Mitchell, Jinyang Li ו-Yifeng Geng מאוניברסיטת ניו יורק ואוניברסיטת Tsinghua; "Comparative Performance of InfiniBand Architecture and Ethernet Interconnect on Intel Microarchitecture-based Clusters", מאת Lars E. Jonsson ו-William Magro מאינטל; "Achieving Mainframe-Class Performance on Intel Servers Using InfiniBand Building Blocks", מאת Oracle; ו-"Improve Performance of a File Server with SMB Direct" שפורסם על ידי מיקרוסופט.
התשובה לשאלה טמונה בשימוש של אינטל בבוחן ביצועים המודד שיעור העברת הודעות message rate) benchmark), כבסיס למדידה ההשוואתית שלה. בחני שיעור הודעות סופרים את מספר ההודעות שנשלחות ממקור ליעד. כדי לספור במדויק את מספר ההודעות, חייב המעבד לתשאל (poll) את הזיכרון שלו כל הזמן כדי לבדוק הודעות. כתוצאה מכך, המעבד נראה עסוק 100% מהזמן, אפילו אם בפועל לא מתבצעת שליחת הודעות. אי לכך, בדיקה זו בבירור אינה מתאימה למדידת נצילות המעבד. יתר על כן, בדיקת אינטל שונתה כדי ליצור הודעות גדולות, בניגוד לבוחן שיעור הודעות טיפוסי אשר מייצר הודעות קטנות מאוד.
אילו הייתה אינטל משתמשת באותו בוחן שיעור העברת הודעות כדי למדוד נצילות מעבד מעל OmniPath, בדומה לבוחן שעשתה מעל אינפיניבנד, הייתה אינטל צריכה לקבל 100% גם מעל OmniPath לעומת 65% עליהם דיווחה. הפער נעוץ בעובדה שבבדיקת ארכיטקטורת ה-OmniPath, אינטל לא השתמשה בשיטת התשאול (Polling), אלא בשיטות אחרות, כמו פסיקה (Interrupt), שמביאות לנצילות מעבד נמוכה יותר.
השורה התחתונה היא שאין ביכולתה של טכנולוגיה המבוססת על העמסה על המעבד (onload) לצרוך פחות מחזורי מעבד עבור פעולות רשת מאשר מקבילתה, טכנולוגית התרת העומסים בחומרה (offload). מוסכם על כולם כי ארכיטקטורת ה-OmniPath צורכת כ-60% מנצילות המעבד (למעשה, באינטל מדווחים על 65% נצילות), וכן ידוע כי אחד היתרונות העיקריים של ארכיטקטורת האינפיניבנד הוא נצילות המעבד המאוד הנמוכה שלה. כל עוד אמות המידה זהות, המספרים מוכיחים שעבודה עם אינפיניבנד מניבה תוצאות טובות יותר.
היתרון של שימוש בטכנולוגיית התרת העומסים בחומרה ובנצילות המעבד הנמוכה שלה, טמון ביכולת להקדיש יותר מחזורי מעבד לעבודת יישומים. תמיכה במספר רב יותר של משימות ברגע נתון, מאפשרת ליישומים לעבוד ביעילות ובמהירות גבוהות יותר. כמובן, ישנם גורמים נוספים המעורבים ביצירת מערכת יעילה ועתירת ביצועים, כולל מנועי האצה מבוססי חומרה, כגון מנועי צבירת והפחתת נתונים, מנועי MPI Tag Matching, ועוד. כל אלה נכללים בפתרונות האינפיניבנד האחרונים בשוק.
ארכיטקטורת האינפיניבנד עושה שימוש במנועי התרת עומסים בחומרה, המסייעים להפחית את נצילות המעבד ולהאיץ ניתוח נתונים. כתוצאה מכך, ביצועי היישומים גבוהים יותר, כמו גם ההחזר הכולל על השקעה. לדור החדש של טכנולוגיית האינפיניבנד התווספה תמיכה במחשוב פנים-רשתי (In-Network Computing) ובזיכרון פנים-רשתי (In-Network Memory); יכולות אלה מאפשרות לרשת לספק מחשוב וזיכרון לכל מקום ברחביה בו מופצים נתונים, והן חיוניות למעבר של מרכז הנתונים מארכיטקטורה ממוקדת מעבד לארכיטקטורה ממוקדת נתונים. בעזרתן, מרכז הנתונים יכול להתגבר על צווארי בקבוק של השהייה, וכן לנתח כמויות גדולות יותר של נתונים בזמן אמת.
מלאנוקס וארגונים אחרים פרסמו מספר מקרי בוחן בעבר, ואלו הראו יתרון ברור לשימוש באינפיניבנד. למשל, "The Ultimate Debate – Interconnect Offloading Versus Onloading" ו"Designing Machines Around Problems: The Co-Design Push to Exascale" מאת Doug Eadline. בכנס OpenFOAM באוקטובר 2016, משתמש שביצע בדיקות על מערכת מבוססת OmniPath, הציג בעיות ביצועים הקשורות בטכנולוגיית ה-onload. הסוגיות המדווחות התמקדו בחוסר היכולת להשתמש בכל ליבות המעבד ביעילות, ובביצועי היישומים הירודים שנבעו מכך. על מנת "לעקוף" את הבעיה, נעשה שימוש רק בחלק מליבות המעבד, מה שאיפשר לליבות שנותרו זמינות לטפל במשימות תקשורת במקום ביישומים. פתרון זה אינו אינטואיטיבי, והוא חוטא למטרה בכך שאינו חותר לניצול מירבי ויעיל של יכולות המעבד.
במצגת מאוקטובר 2016, אינטל התייחסה לטענות לגבי ביצועי היישומים הנמוכים כאל דיווחי "FUD" (ראו איור 4). ככלל, טכנולוגיה המבוססת על התרת עומסים בחומרה צריכה לאפשר ביצועי יישומים גבוהים יותר. ביישומים בהם נדרשת תקשורת נתונים ברמה בסיסית, פער הביצועים בין טכנולוגיית ה-onload וטכנולוגיית ה-offload אמור להיות מינימלי. כל תוספת של תהליכי תקשורת נתונים מגדילה את פער הביצועים. מי שירצה להסוות פער זה, יוכל פשוט להפחית את כמות ליבות המעבד בהן משתמש כל שרת, ולאפשר לליבות הזמינות לטפל במשימות שאינן קשורות ביישומים, כמו למשל ניהול רשת. במקרה זה, הפער בין ביצועי ההתרה וההעמסה יהיה נמוך יותר (בהנחה שגם טכנולוגיית ההתרה מוגבלת למספר קטן יותר של ליבות מעבד). מלאנוקס הצליחה לשחזר את התוצאות שהציגה אינטל באיור 4 באמצעות שיטה זו. כמובן, שיטת בדיקה זו אינה משקפת את יכולות הביצוע של המערכת או את הקריטריונים שעומדים לנגד עיניו של המשתמש בבואו לרכוש אותה. מובן שאף משתמש לא ירכוש שרת בידיעה כי יוכל להשתמש רק בחלק מליבות המעבד הזמינות.
בנוסף, מלאנוקס עידכנה את תוצאות בדיקות האינפיניבנד שפורסמו במקור, והשוואת הביצועים הכוללת מוצגת באיור 5.
לצורך מבחן הביצועים העדכני, מלאנוקס השתמשה באשכול מחשבים שכלל 32 שרתים, כאשר בכל אחד מהם שני מעבדי Intel Xeon E5-2697A ו-16 ליבות בכל מעבד. במערך בדיקות אחד, נעשה שימוש ב-28 ליבות מעבד בלבד מבין 32 הליבות הזמינות, ובמערך הנוסף, נוצלו כל 32 הליבות הזמינות בכל אחד מהשרתים. התוצאות מאששות את הטענות, על פיהן הפחתת מספר הליבות הזמינות ליישומים משפרת את ביצועי טכנולוגיית ה-onload, אם כי במחיר גבוה (המשתמש נאלצץ לשלם על ליבות שלא נעשה בהן שימוש).
יתר על כן, התוצאות משקפות את הביצועים המובילים של טכנולוגית ה-offload (אינפיניבנד). אינטל לא הציגה תוצאות עבור 32 צמתי רשת (nodes), כפי שניתן לראות באיור 4, ואיור 5 מרמז מדוע. ביצועיה של טכנולוגיית ה-OmniPath אינם משתפרים במערך בדיקה הכולל יותר מ-16 צמתי רשת, בשעה שטכנולוגיית האינפיניבנד מנצלת את תוספת הצמתים היטב, ומאפשרת ביצועי יישומים גבוהים יותר ב-30% בשימוש ב-28 ליבות מעבד, וב-40% כשכל 32 ליבות המעבד מנוצלות.
בעוד שבעלי היישומים מייחסים חשיבות גבוהה יותר להשגת ביצועים אבסולוטים, תוך התמקדות במהירות בה יוכלו לנתח ולפתור בעיות מחקריות והנדסיות, מנהלי מרכזי נתונים צפויים להיות מוטרדים יותר מרמת הביצועים הכוללת, תוך התחשבות בשיקולי עלות מול יכולת ביצוע. תוצאות הבדיקות באיור 5 מראות בבירור כי טכנולוגיית האינפיניבנד הנמדדת באשכול מחשבים המכיל 16 צמתי רשת, מתעלה בביצועיה על טכנולוגיית ה-OmniPath, כשזו נמדדת באשכול מחשבים בו 32 צמתי רשת. נתון זה שווה ערך להפחתה של כ-40% מעלות המערכת (כולל שרתים, מעבדים, זכרון וציוד קישוריות) הנדרשת לצורך השגת אותם ביצועי יישומים.
בבואנו לבחור בין קישוריות העושה שימוש בהתרת עומסים בחומרה (offload) לבין קישוריות הפועלת באמצעות העמסה על המעבד (onload), המספרים האמיתיים מצביעים על אינפיניבנד כטכנולוגיית הקישוריות המובילה של ימינו עבור פלטפורמות מחשוב ואחסון עתירות ביצועים.
