



 דניאל לייזרוביץ, חברת אי. אס. אל.
דניאל לייזרוביץ, חברת אי. אס. אל.
רוב מערכות המכשור הרפואי שבשימוש או בפיתוח היום מבוססות לחלוטין על תוכנה. בשנים האחרונות גדלה מאד מורכבות התוכנה שמפעילה מכשור רפואי מודרני, ולא נדיר לראות יישומים המפעילים מיכשור רפואי, המכילים מיליוני שורות קוד, ואפילו מכשירים קטנים יחסית כגון משאבות עירוי (Infusion Pumps) מכילים עשרות אלפי שורות קוד.
מצד אחד, ברור לכל שהיישומים הללו צריכים להיות נקיים לחלוטין מטעויות תכנות, ואפילו באג פשוט יכול לגרום לסכנת חיים, ומצד שני, ידוע שקשה מאד לייצר בזמן סביר מערכת המכילה מיליוני שורות קוד שתהיה נקיה משגיאות תכנות.
המחלקה האחראית על מכשור רפואי במנהל המזון והתרופות האמריקאי (FDA) והנקראת (Center for Devices and Radiological Health) כמו גם מקבילותיה במדינות אחרות, מבקשת מהיצרנים שמוצריהם מכילים תוכנה לבצע תהליכים מוסדרים ומתועדים של אימות ותיקוף (verification and validation) לכל מרכיבי התוכנה במוצר.
השיטות המסורתיות והמקובלות לביצוע אימות ותיקוף ותוכנה הינם “בדיקות”, המבוצעות על ידי מחלקת ה- QA (בדיקות “קופסא שחורה”) וסקירת קוד המבוצעת על ידי מחלקת הפיתוח (בדיקות “קופסא לבנה”).
החסרונות של סקר קוד על בסיס קוד גדול ברורים לרובנו אינטואיטיבית: סיבוכיות קוד. הערך המייצג מורכבות של תוכנת המחשב, למשל, ערך הסיבוכיות הציקלומטית (Cyclomatic Complexity Number – CCN) המייצג את מספר מסלולי הבקרה הנפרדים ברוב היישומים המודרניים מצוי מעבר ליכולת הקליטה של האדם הסביר.
בסיס קוד של 200 אלף שורות מכיל בערך 10 בחזקת 12 מסלולי בקרה אפשריים, מספר בן 13 ספרות (לצורך הפרופורציה, גודלו בערך פי 3.3 ממספר הכוכבים בגלקסיית שביל החלב).
סיבוכיות הקוד משליכה ישירות גם בדיקות ה- QA, ככל שערכי הCCN גבוהים יותר, כך נדרשים יותר תסריטי בדיקה ייחודיים על מנת לבדוק את כל מסלולי הבקרה האפשריים של התוכנה הנבדקת, ועדיין אנו מוגבלים למספר התסריטים שניתנים לביצוע מעשי במעבדת הבדיקות בזמן המוגבל שהוקצה לבדיקות. מקובל לראות במערכות שעוברות בדיקה במעבדת ה – QA נתוני כיסוי הקוד (Code Coverage) בשיעור 70%-80%, וזאת בנתון “אחוז שורות שהורצו בפועל” (Line Coverage). כאשר מודדים את אחוז הנתיבים בקוד שכוסו (Path Coverage) לא נדיר לראות שיעור של 30% – 40%.
בעייתיות זו לא נעלמה מעיניהם של אנשי ה- FDA, ובשנים האחרונות הם מאמצים כפתרון מומלץ ונדרש לאימות ותיקוף תוכנה את השיטה הידועה כ- “ניתוח קוד סטאטי של קוד המקור”, כפי שעשו לפניהם חבריהם בגופי רגולציה אחרים כגון מנהל התעופה הפדראלי (FAA) ומועצת הפיקוח על אמצעי תשלום (Payment Card Industry Security Standards Council).
“ניתוח קוד סטטי” הינו תהליך סריקה אוטומטי של קוד המקור על ידי תוכנת בדיקה ייעודית, המתבצע ללא הרצה בפועל של התוכנית, ואשר לוקח תוכנית ומוצא תכונות או שגיאות תכנות הנוצרות ללא תלות בקלט, בכל מסלול שמגיע לנקודה מסוימת בתכנית.
בהתבסס על מחקרים אקדמיים וניסיון מעשי מ-35 השנה האחרונות, וכשמשקללים מאמץ ועלות (כולל עלות זמן באינטגרציה ועקומת לימוד) מול תועלת לפרויקט בד”כ מגיעים למסקנה, שניתוח קוד סטאטי הינה השיטה היעילה והמהירה ביותר למציאת שגיאות תכנות בקוד המקור.
הקריטריונים והשיקולים לבחינה מקצועית של כלי מתאים מנקודת מבטו של מהנדס התוכנה
מידע שהצטבר בידינו לאחר שנות ניסיון רבות בתחום ופידבק שהתקבל מכ-80 פרויקטים של הטמעת כלי ניתוח קוד סטאטי בישראל (רובם ביישומים רפואיים וביטחוניים), מאפשר סקירת השיקולים והקריטריונים המתאימים.
ראשית, חשוב להבין שקיימים מספר סוגים של כלים, השונים מהותית אחד מהשני. הסוג הראשון – כלים פשוטים מבוססי התאמת תבניות טקסטואליות (Pattern Matching) או בקיצור PMA. הסוג השני – כלים מתוחכמים מבוססי אנליזת משוואות זרימה (Data Flow Analysis) או בקיצור DFA. סוג שלישי מהווה איחוד שני הסוגים המוזכרים לעיל לתוך ממשק אינטגרטיבי אחד.
הכלים הפשוטים מסוג PMA זולים יותר ופשוטים להטמעה, הם בד”כ לא מחייבים שהפרויקט יהיה ניתן לבניה (Buildable) ומתבססים על עיבוד התוצרים של הנתח הטקסטואלי (Lexical parser), דהיינו, על השלב הראשון והבסיסי בתהליך הקימפול. ולמרות שכלים אלו שימושיים באיתור סגנון כתיבה לקוי, למשל ביטול קטע קוד על ידי השמתו בהערה בסגנון /* —–*/ במקום ביטולו באמצעות #ifdef —–#endif כפי שנכון יותר לעשות, ואכיפת סטנדרטי כתיבה (Coding Standards) כגון MISRA C או ++JSF.
כלים מסוג זה מצליחים רק לעיתים נדירות למצוא שגיאות חמורות מהסוגים שבאמת “מפיל את המערכת” כגון, דליפות זיכרון, שימוש במשתנים בלתי מאותחלים, שחרורי זיכרון כפולים או Buffer Over Run, ומצבים בהם אותן שגיאות מתרחשות במעבר בין פרוצדורות ומודולים שונים. יתרה מזאת, כלי ה- PMA מייצרים כמות אדירה של התראות שווא (False positive) המקשות מאד על העבודה והופכות את הכלי והטמעתו לבעיה בפני עצמה ולא לפתרון.

תמונה 1
דוגמא אופיינית להתראת שווא הנובעת מחוסר יכולת של כלי PMA להבין את זרימת התוכנית נראה בתמונה 1.
כאן אנו רואים כיצד מתקבלת התראה על שימוש במשתנה לא מתוחל, כאשר בפועל, השימוש במשתנה כלל לא קורה במסלול הזרימה של התוכנית. כלי מבוסס DFA ימנע מהתראה ובכך יקטין את ה”רעש” וכמות התראות השווא.
כלי ניתוח קוד סטאטי מבוססי DFA מסוגלים לכסות 100% מסך הנתיבים האפשריים בתוכנה נתונה, בהסתייגות ממקרה בו מדובר בתוכנות גדולות ומורכבות, בהן אפשר להגיע באופן תיאורטי ל”בעיית העצירה”. במצב זה, כיסוי של 100% ידרוש זמן ריצה אינסופי של תכנת הבדיקה, אך שימוש באלגוריתמי קירוב מאפשר להגיע למצב בו הכיסוי חסר אך ורק ב-0.0001 מהנתיבים האפשריים.
לאחר שהבנו שלא רצוי ולא ניתן לעמוד בדרישות רגולטריות או דרישות איכות בכלל בעזרת כלי מבוסס pattern matching בלבד וניתוח קוד סטאטי מודרני משמעותו שימוש ב- Data Flow Analysis נבחן כמה משגיאות התכנות הניתנות לזיהוי בעזרת השיטה, ולהלן נביא מספר דוגמאות אופייניות:
חלוקה באפס (תמונה 2)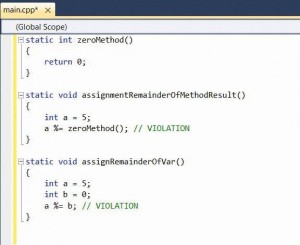
גלישת חוצץ Buffer Over Flow (תמונה 3)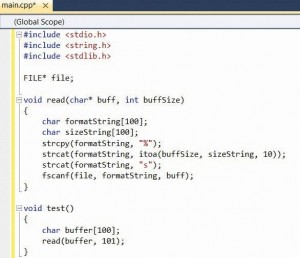
Null Pointer Dereferencing
(תמונה 4)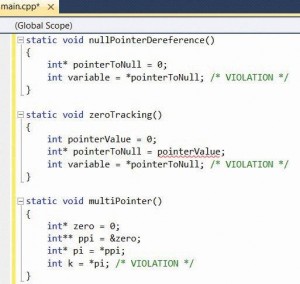
אלו רק דוגמאות ספורות מתוך מאות דוגמאות אפשריות לשגיאות תכנות אופייניות שלכלי ניתוח קוד סטאטי יש יכולת של כמעט 100% לגלותם במידה והם קיימות.
שיקולים בבחירת הכלי
ככלל ניתן לומר, שההצלחה של בחירת הכלי תלויה בתשובה לשתי השאלות הבאות:
1. האם הכלי יאומץ ע”י המפתחים כחלק אינטגראלי מתהליך הפיתוח.
2. האם הכלי ישתלב לסביבת העבודה ולתהליכי העבודה והפיתוח בארגון.
ברמה הבסיסית והעליונה יותר המענה לשאלות אלו נמצא בתשובות לשאלות כגון: האם הכלי ישתלב כתוסף ל-IDE שלנו? האם יש לו שרת הפצת דו”חות? האם ההערות מסונכרנות היטב לקוד המקור? האם הכלי יסנכרן עם מערכת ניהול ובקרת התצורה ואו עם מערכת ניהול ומעקב הבאגים שבה אנו משתמשים? מהו מודל הרישוי והאם הוא מתאים ליכולות הארגון?
ברמה המקצועית, ישנם שיקולים נוספים, חשובים הרבה יותר:
דיוק – אי אפשר להגזים בחשיבות מידת הדיוק של הכלי. דיוק הוא לב ליבו של העניין, שכן אם המפתחים יזהו חוסר דיוק הם ימנעו משימוש ואימוץ אמיתי של הכלי.
דיוק בהקשר זה מוגדר כמקובל בתורת האינפורמציה כ- (Precision = TP /(TP + FP כאשר TP הנו מספר התראות האמת ו- FP מספר התראות השווא, דהיינו, אם נקבל תוצאה = ל-100% הכלי לא הנפיק ולו התראת שווא אחת.
לצערנו, תוצאה מושלמת של 100% אינה מעשית בטכנולוגיה הקיימת כיום, אם כי הכלים המסחריים הקיימים כיום מתקרבים לתוצאות של 80% ואפילו 90% במקרים מסויימים.
אם בתורת האינפורמציה עסקינן, לא נוכל להתעלם מבן לוויתו התמידי של ה-”דיוק”: מידת ה-”החזר” (Recall) המוגדר כך (Recall = TP / (TP + FN, כאשר TP הנה מספר התראות האמת ו- FN המספר המוחלט של התוצאות השליליות השגויות (אי זיהוי בעיות אמיתיות הקיימות בקוד).
כלי שמשיג רמת “החזר” של 100%, בעצם מוביל לאבחנת מלוא הבעיות האמיתיות, ואולם כאמור, אין בנמצא כיום כלי העונה לדרישה זו למרות שמספר כלים הקיימים כיום מתקרבים לכך וסוגרים את הפער במהירות.
כיצד נבדוק שהכלי אכן מדויק? מאין ניקח את הנתונים להציב במשתנים? ראשית חשוב להעיר, ששימוש בכלי מסחרי בו היצרן אינו מאפשר תקופת בדיקה מקיפה וארוכה לפני הקניה לצרכי בחינות כאלה בעייתי מיסודו, אבל בהנחה שיש לנו גישה לגרסת בדיקה, הדרך המקובלת לבחינה כזאת היא לעשות שימוש בגרסאות קודמות של פרוייקט ישן ויציב שקיים בארגון, שכבר נוקה משגיאות ומתאפשרת בו גישה לתיעוד באגים שתוקנו, על מנת לבחון את יעילותו של הכלי בזיהוי הבעיות הידועות.
אפשרות נוספת, עדיפה יותר, היא לקחת פרויקט קוד פתוח גדול וידוע שקיים כבר שנים רבות ומעורבים בו כמות גדולה של מפתחי קוד פתוח בני סמכא, ויש לו גרסאות קודמות רבות. לפרויקט כזה, (למשל Apache או אפילו קרנל הלינוקס עצמו) יש תיעוד של אלפי דפקטים ושגיאות תכנות רלוונטיות וגרסאות קוד ישנות שלו בהם מופיעים אותם דפקטים ניתנות להשגה בקלות על ידי שיטוט מהיר בארכיוני הפרויקט.
בחברה שלנו אנו משתמשים בקוד המקור של גירסאות ישנות של פרוייקט הקוד הפתוח SPLINT לצרכי בדיקות רגרסיה של כלי ניתוח קוד מכל סוג שהוא. מדובר למעשה בפרוייקט קוד פתוח של כלי ניתוח קוד סטאטי! מכיון שהפרוייקט עצמו הוא כלי בדיקה שנכתב בידי אנשים המכירים כלי בדיקה שונים ומודעים לחשיבות הנושא, הבאגים שנותרו בקוד הם באגים שמטבעם קשים מאד לגילוי בכל שיטה מקובלת, והמטלה לאתר את אותם באגים שחמקו מעיני המפתחים המנוסים מטילה עומס רב על הכלי אותו אנו בודקים ומאפשרת לבחון את רמת דיוקו היטב ובתנאים מורכבים.
שימוש בפרויקט קוד פתוח גדול ומסובך מאפשר לנו גם לבחון בעיה נוספת המפריעה לאימוץ כלי ניתוח קוד סטאטי בארגונים – בעיית הביצועים.
תהליך ניתוח קוד סטאטי מנתח תוצרים של תהליך ה-Build, דהיינו, קבצי ביניים של הקומפיילר והלינקר. הכלי מבצע העתקה, עיבוד נוסף, פענוח וניתוח על אותם קבצי ביניים, ובהמשך בודק כמות אדירה של תרשימי זרימה אפשריים בקוד.
תהליך זה עשוי לארוך פי 10 ויותר מתהליך Build רגיל, כאשר משך כל זמן הבדיקה המפתח מושבת מעבודה.
יצרני הכלים מתמודדים עם בעיה זו בדרכים שונות, שהנפוצות בהם הינם ניתוח אינקרמנטלי, מיקבול התהליך, שימוש במאיצים ייעודיים כגון Electric Cloud ועוד. כלים אחרים, כגון Parasoft, מאפשרים המשך עבודה רגיל ללא הפרעות בעוד האנליזה מתבצעת ברקע.
בדיקת פרויקט המכיל כמה מיליוני שורות כמו קרנל הלינוקס, מהווה מדד מצויין לקלות הזנת פרוייקט לכלי ולרמת הביצועים שלו, ומאפשרת להעמיד במבחן המציאות את שאלת שילובו היומיומי בארגון מבלי שיהפוך לפיל לבן, שיופעל רק כאשר המפתח יוצא לכמה ימי חופש עקב פרק הזמן הממושך הנחוץ לצורך הפעלתו.
לסיכום, חברות, המפתחות מיכשור רפואי יכולות להפיק תועלת רבה ולשפר מאד את סיכוייהן לעבור את המבדקים הנחוצים לקבלת אישור ה-FDA כבר בפעם הראשונה, אם ישתמשו גם בכלי ניתוח קוד סטאטי.
בחירה מושכלת, הבאה לאחר בחינה מעמיקה ומקצועית של הכלים בתנאי שטח אמיתיים כפי שפורטו לעיל, תבטיח הטמעה חלקה ואימוץ נרחב בארגון.
הסקירה נכתבה על ידי דניאל לייזרוביץ מחברת אי. אס. אל. מערכות תוכנה בע”מ (Engineering Software lab), “המרכז הישראלי לניתוח קוד סטאטי ובדיקות דינאמיות”, החברה מתמחה בפיתוח, הטמעה, הדרכה וייעוץ של כלי בדיקה וניתוח קוד מקור עבור שפות
ומלווה חברות מכשור רפואי בתהליכים הנדרשים להשגת הסמכת FDA מההיבטים של אימות ווידוא קוד מקור.