




 תמצית מנהלים: הדרישה לציוד אבטחה מתקדם לסרוק זרמי נתונים לצורך בדיקת תוכן זדוני. בקצב העברה מציבה אתגרים משמעותיים ליצרני אבטחת רשתות. ציוד האבטחה, הכורע תחת עומס הקצבים של המידע ברשתות הנוכחיות, סביר שלא יזהה התקפות ובכך מגדיל את הסיכונים שבפרצות אבטחה. בעוד סריקה בקצב גבוה, הידועה כ- (Deep Packet Inspection), קיימת כבר היום הרי שהיא דורשת חומרה ייעודית כדי לפעול במהירות גבוהה, דבר המוביל לעלויות גבוהות של פיתוח ותחזוקה.
תמצית מנהלים: הדרישה לציוד אבטחה מתקדם לסרוק זרמי נתונים לצורך בדיקת תוכן זדוני. בקצב העברה מציבה אתגרים משמעותיים ליצרני אבטחת רשתות. ציוד האבטחה, הכורע תחת עומס הקצבים של המידע ברשתות הנוכחיות, סביר שלא יזהה התקפות ובכך מגדיל את הסיכונים שבפרצות אבטחה. בעוד סריקה בקצב גבוה, הידועה כ- (Deep Packet Inspection), קיימת כבר היום הרי שהיא דורשת חומרה ייעודית כדי לפעול במהירות גבוהה, דבר המוביל לעלויות גבוהות של פיתוח ותחזוקה.
גישה מבוססת תוכנה המנצלת את יתרון ריבוי הליבות של Intel Architecture, יכולה לספק פתרון חסכוני, מדרגי (scalable) וגם שיש לו את הגמישות להתפתח ביחד עם הדרישות המשתנות של המערכת.
תוכנת ™Sensory Networks HyperScanלהתאמת תבניות , שתוכננה עבור מעבדים עם ליבה יחידה וגם לאלו עם ליבות מרובות, מציגה פתרון DPI מבוסס תוכנה שיכול לגדול החל מ-1Gbps ועד ל-160Gbps בתלות במספר הליבות שבשימוש. ע"י יצירת טכנולוגיית DPI אופטימאלית למעבדים מרובי ליבות, חברת Sensory Networks מספקת פתרון תוכנה משתלם לסריקת תוכן בקצב בציוד אבטחה הנע מהתקנים ברשתות קטנות ועד לאלמנטים ברשתות גדולות.
Deep Packet Inspection
ארכיטקטורות חדשות של מעבדים בקצבי שעון גבוהים יותר, זיכרונות מטמון גדולים יותר ותכונות מתקדמות אחרות, מאפשרות לציוד אבטחה ברשתות לשלב יכולות שקודם נמצאו במערכות הקצה. ללא המגבלה של יכולות bridgin ו-forwarding בלבד, האלמנטים כיום של הרשת סורקים חבילות בזמן שהן עוברות ברשת. תוך ניצול טכנולוגיה זו, מנהלי הרשת משלבים מערכות לגילוי ומניעה של חדירות (IDS/IPS) וסורקים רשתיים לאנטי וירוס ותוכנות זדוניות וזאת לצד ה-firewall המסורתי. במקרים מסוימים, כמה פונקציות אבטחה מוטמעות לתוך ציוד ה-Universal Threat Management
(). שלא כמו ה-firewall המסורתי, שרק מסתכל לתוך הכותרות (headers) של החבילות, סוג מתקדם זה של ציוד משתמש בטכנולוגיית DPI כדי לבחון את התוכן של כל החבילה על מנת לגלות איומים. במקום לבסס החלטות אבטחה על ערכי השדות בכותרת של החבילה, טכנולוגיית ה-DPI מאפשרת ליישום האבטחה להסתכל עמוק לתוך זרם הנתונים ולנסות לזהות כוונות להזיק. לבחינה יותר מפורטת זו של זרם הנתונים יש עלות נוספת – ככל שסריקת זרם הנתונים יותר אינטנסיבית, היא מעמיסה את המעבד ויכולה להיות לא ישימה ככל שעומס התעבורה עולה. לפיכך, יעילות ה-DPI ככלי תלויה מאד בתפקודו תחת עומס. מערכת שמתפקדת היטב בתנאים תאורטיים אבל נכשלת בזמן תעבורה אמתית כבדה יוצרת בעיית אבטחה גדולה. דוגמה אנלוגית – נניח שבביקורת גבולות במדינה יעצרו כל רכב שחוצה את הגבול לחיפוש מדוקדק. בעוד שגישה זו יכולה לספק אבטחה נוספת במעברים בהם התנועה דלילה, הרי שהיא תיצור עומסים בנקודות מעבר גדולות – דבר שיחייב להחזיר חלק מהרכבים או יותר גרוע, רכבים יעברו ללא בדיקה בכלל וזאת כדי להוריד את העומס. בצורה דומה זה מה שיקרה בציוד האבטחה שלא יכול להתמודד עם עומסי התעבורה הנכנסים. חבילות יכולות להיזרק מהתורים ובכך יגרמו לבקשות Re-transmit ממערכות הקצה, דבר שיחריף את המצב. כדי להימנע ממצב זה ולהגדיל ביצועים, על יצרני אבטחת רשתות להסתמך על חומרת עזר ייעודית ל-DPI שתאפשר סריקה מפורטת במהירות הרשת. חומרה ייעודית זו יקרה, קשה לשימוש ובד"כ מחייבת פרדיגמה שונה של פיתוח התוכנה. הזמינות של מעבדים מרובי ליבות יצרה את ההזדמנות ל-DPI מבוסס תוכנה יעיל שמתקרב ואפילו טוב יותר בביצועים מהפתרונות מבוססי חומרה.
התאמת תבניות (Pattern Matching)
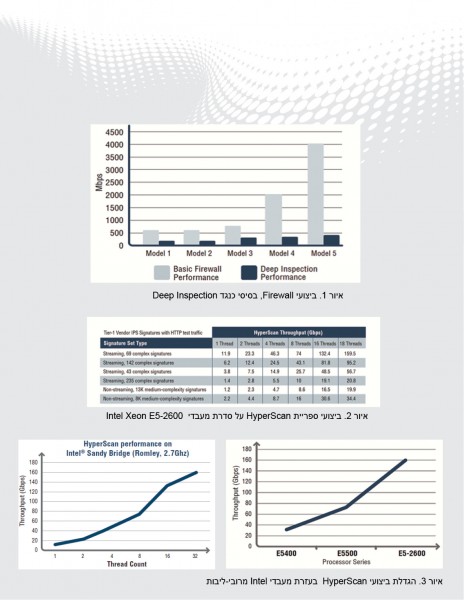
רעיון מרכזי ביישומי DPI רבים הוא השוואת תבניות, היכולת להשוות ולהתאים זרם נכנס של בתים (byte stream) מול בסיס נתונים של תבניות או דפוסים עבריינים הנקראים חתימות. חתימות אלו מייצגות תוכן זדוני פוטנציאלי ויכול להיות מהצורה של מחרוזת (string) מילולית פשוטה או תבניות מורכבות יותר כמו סידור מסוים של בתים הנקטע על ידי כמות משתנה של מידע אחר לא רלוונטי. סוג החתימה האחרון מתואר תכופות באמצעות צורה כלשהיא של ביטויי תחביר רגיל ולעיתים משולב עם תחביר ייחודי (proprietary). בעוד חיפושים מילוליים עצמם יכולים להיות אינטנסיביים, חיפושי ביטויים רגילים דורשים משאבי מעבד משמעותיים כך שהם הופכים לבעייתיים לביצוע במהירות גבוהה, במיוחד בחיפוש של אלפי חתימות. איור-1 מראה את ההבדלים הבולטים בביצועים של מערכת לדוגמא שמריצה firewall שמבצע סינון בסיסי של חבילות, ואותה מערכת מריצה DPI מול קבוצה של כללים ותבניות.
התאמת תבניות פשוטה צריכה להיות מסוגלת לבצע השוואה של זרם הבתים הנכנס מול בסיס נתונים של חתימות וזאת עם ביצועים דטרמיניסטיים ללא תלות במספר החתימות. במילים אחרות, משווה התבניות נדרש לביצועי השוואה הרבה יותר טובים מהשוואה ישירה בצורה סדרתית או רציפה של זרם הנתונים הנכנס מול כל חתימה במבנה הנתונים. הליכה קדימה-אחורה בתוך זרם הנתונים מאד לא יעילה מבחינת הזיכרון מטמון ולא יכולה לגדול ככל שמספר החתימות גדל. כמה בודקי התאמת תבניות מבוססי תוכנה התגברו על גישת התאמה ישירה זו ע"י שימוש אלגוריתם מבוססי – trie כאשר קבוצת התבניות שנבדקות מסודרות בתוך מבנה נתונים שממפה את הקשרים בין התבניות. כאשר חבילה חדשה נכנסת, התוכנה רק סורקת את הטבלה בחיפוש התאמות, בדומה לחיפוש כתובת IP. בעוד שחיפוש זה מייצג שיפור ככל שמספר התבניות גדל ביחס לגישות המבוססות על חיפוש ישיר, יש לו גם את החסרונות שלו. בתלות במספר החתימות ובגודל זיכרון המטמון של המעבד, שימוש באלגוריתם trie בצורה זו עלול לדרוש מספר גדול של גישות לזיכרון לכל חבילה כאשר במקרה הגרוע מדובר על גישה לזיכרון עבור כל בייט של החבילה הנכנסת, דבר שיכול לגרור ביצועים שהם לא טובים יותר ביחס לגישה הישירה שאותה רוצים להחליף. לכן, בעוד טכנולוגיית DPI הופכת למורכבת יותר, היא גם מציבה אתגר ביעילות כאשר נדרשת הרחבה בביצועים. ככל שהבדיקה עמוקה יותר ופרטנית – נדרש יותר עיבוד ולכן נדרש למצוא אלטרנטיבות למנגנון הנוכחי של הסריקה.
HyperScan-ספריית השוואת תבניות
בעוד משווי תבניות רבים בתעשייה ממומשים בעזרת גישות רציפות פשוטות, או בעזרת אלגוריתם שלא מנצלים ביעילות את זיכרון המטמון או ע"י שימוש חומרה שמציגים אתגרים בזמני תגובה (latency) וביכולת מידרוג, יצרני ציוד יכולים לנצל את היתרון של פתרונות התוכנה של Sensory Networks להשוואת תבניות המספקים פתרון חסכוני ובעל יכולת מדרגית (scalability).
HyperScan היא ספריה מבוססת ריבוי תהליכים להשוואת תבניות שלא תלויה במערכת ההפעלה. היא ניתנת לשילוב בקלות והיא מחליפה את libPCRE, לא רק תוך כדי תמיכה בתחביר המבוסס על קבוצה גדולה יותר של Perl Compatible Regular Expressions (), אלא עם ביצועים הטובים בסדר גודל. כאשר
היא משולבת בפלטפורמות מבוססות
Intel Architecture, מנצלת תכונות כמו hyperthreading, receive side scaling ופקודות SIMD כדי לספק ביצועי סריקה עד ל-160Gbps. מלבד ביטויים רגולריים קלסיים, HyperScan תומכת במגוון רחב של חתימות אחרות הנדרשות למרבית יישומי אבטחה ונתונים ברשת, כולל עוגנים, character classes ו-Bounded repeats. שלא כמו גישות הסריקה הרציפות שהולכות הלוך ושוב על זרם המידע הנכנס לכל תבנית בבסיס הנתונים, הביצועים של HyperScan לא תלוי ישירות במספר התבניות שמחפשים. זרם הנתונים נסרק למציאת כל הביטויים הרגילים שנמצאים בסט החתימות בו"ז וההתאמות שנמצאו מוחזרות ליישום האבטחה. הביצוע של HyperScan הוא דטרמיניסטי ואינו מציג תנודות דרסטיות בביצועים, כפי שקורה במערכות הסריקה המסורתיות.
HyperScan מסוגלת לסרוק כל חבילה נכנסת באופן עצמאי או כזרם נתונים משולב מחדש וזאת כדי לזהות התקפות שמתפרסות על פני כמה חבילות. יישום האבטחה, למשל, יכול להרכיב מחדש זרם TCP ולהפעיל את ספריית HyperScan לסריקה. HyperScan עוקבת אחר כל ההתאמות החלקיות, כך שהוא יכול להפעיל מחדש סריקה מהמקום שבו הופסק כאשר נתונים נוספים מגיעים בזרם זה.
חתימת זיכרון קטנה
מרכיב מרכזי של כל פתרון לחיפוש ביטויים רגילים הוא המהדר, אשר מעביר קבוצת החתימות, תוך כדי הקטנתה, לקוד מבוסס בתים שניתן לקריאה על ידי המנוע להשוואת תבניות שרץ על המעבד. מהדרים מסוימים מייצרים טביעת רגל קטנה בזיכרון (memory footprint), אבל אלה נוטים להיות עבור מנועי חיפוש שעובדים בצורה רציפה, שבהם היתרון של מבנה נתונים קטן מתבטל מול היכולת המדרגית הנמוכה.
מהדרים אחרים בונים מבני נתונים גדולים ומורכבים, המכילים מידע יחסי לתבניות כדי לאפשר חיפוש של אלפי חתימות שיבוצעו במקביל, אך על חשבון חתימת זיכרון גדולה. מבנה נתונים המאפשר סריקה מקבילה הוא מטבעו גדול יותר שכן הוא חייב לאחסן את היחסים בין כל התבניות, שעלול להוביל לגידול אקספוננציאלי בהתאם לאופי של החתימות. החיסרון הוא שמבנה נתונים גדול יכול לגלוש מזיכרון המטמון ולהוביל לגישות זיכרון מסיביות, לעתים קרובות גישה אחת לכל בייט שמעובד.
בעוד שתי גישות אלה עשויות לייצר תוצאות טובות בתרחישים מתוכננים, הם עלולים להוביל לביצועים תת אופטימליים כאשר פועלים בעולם האמיתי עם אלפי חתימות ואלפי זרמי נתונים. לעומת זאת, המהדר לביטויים רגילים של HyperScan והמנוע תומכים בסריקה מקבילית של אלפי חתימות ללא טביעת רגל גדולה בזיכרון שהיא אינהרנטית בדרך כלל במבני נתונים של סורקים מקביליים רגילים. באמצעות שימוש בטכניקות קנייניות, המהדר של HyperScan בונה מבנה נתונים הנפרד מהחלקים המרכזיים של קבוצת החתימות, וכתוצאה מכך טביעת רגל בזיכרון של מבנה הנתונים קטנה מספיק כדי להיכנס לזיכרון המטמון של המעבד עבור רוב מקרי שימוש. על ידי שמירה על מסד הנתונים קומפקטי, גישות לזיכרון חיצוני נדרשות לעתים רחוקות תחת פעולה רגילה. בהתאם להגדרת תצורה, גישות לזיכרון חיצוני נדרשות לעיתים קרובות רק כשמתרחשת התאמה.
גידול לינארי בביצועים
הארכיטקטורה המבוססת על ריבוי תהליכים של HyperScan מנצלת את היתרון של ריבוי תהליכים סימטרי כדי להגדיל ביצועים באופן ליניארי עם מספר תהליכי החומרה (h/w threads) שבשימוש. כל סריקה רצה באופן עצמאי ללא קשר לסריקה אחרת, דבר המאפשר עיבוד במקביל של זרמי נתונים השונים מבלי להשפיע בצורה שלילית על הביצועים האחרים.
ריבוי-תהליכים (Multi-threading) בעצמו אינו מספיק כדי להבטיח ביצועי סריקה טובות. בעוד משווי תבניות אחרים הממומשים בתוכנה יכולים להיות גם מרובי תהליכים, התחרות בין התהליכים על מבנה הנתונים המשותף יכולה להגביל את היכולת להרחיבה.
מסד הנתונים של HyperScan, בעל טביעת רגל קטנה בזיכרון שבשילוב זיכרונות מטמון גדולים במעבדים מבוססי – IA, המשמעות היא שכל תהליך סורק מידע מול מבנה נתונים שנמצא אצלו בזיכרון המטמון המקומי. דבר זה מוריד באופן דרמטי את כמות התחרות על זיכרון משותף במערכות מרובות ליבות, מה שמוביל להתקדמות לינארית יותר מבלי "שיטוח" עקומת הביצועים כפי שקורה בד"כ כשמספר התהליכים גדל.
בוחן ביצועים לסדרת Intel Xeon E5-2600
מדידת הביצועים של השוואת תבניות יכולה להיות מושפעת מכמה גורמים. הסוגים ומספרם של החתימות, התוכן של תעבורת המידע הנכנס ומספר ההתאמות או ההתאמות החלקיות שנמצאו במידע – כל אלו יכולים להשפיע על תוצאות בוחן הביצועים. כדי שהתוצאות יהיו בעלות משמעות, הבדיקות חייבות להשתמש בחתימות אמיתיות ותעבורת רשת אמיתית. Sensory Networks ערכו השוואות ביצועים לספריית HyperScan הפועלת על פלטפורמה מבוססת על סדרת מעבדי Intel Xeon E5-2600 עם תושבת כפולה וארבע ליבות
(סה"כ 8 ליבות) באמצעות מערכת שלמה של חתימות IPS עדכניות שמקורן ביצרני ציוד אבטחה מובילים. הקלט נלקח מתעבורת HTTP אמיתית שנלכדה והורצה שוב מקובץ PCAP. יישום פשוט נכתב כדי לקרוא את קובץ ה-PCAP לתוך הזיכרון ולהפעיל את ה-APIs
של-HyperScan חבילה אחרי חבילה תוך כדי סימולציה של יישום רשת אמיתי כמו IPS או web proxy. המידע הותאם ל-streaming mode למקרים שבהם איומים יכולים להתפרס על כמה חבילות מידע, וכן ל-non-streaming mode לאיומים שיהיו מרוכזים בגוש אחד של נתונים. קבוצת החתימות שבה נעשה שימוש כללה גרסאות מרובות של “” וגם קבוצות URI. כל החתימות עברו קומפילציה לתוך מבנה הנתונים של ה-runtime תוך פחות משלש שניות. היישום של בוחן הביצועים מדד במיוחד את השוואת התבניות ברמה הגולמית, תוך כדי הוצאה מהמדידה זמן קריאת קובץ ה-PCAP וכן את זמן ה-pre/post scan processing. כל המידע ששימש להשוואת התבניות היה בזיכרון.
התוצאות (באיור-2) מראות יכולת מדרוג או הרחבה לינארית עד 8 תהליכים, והתיישרות קלה כאשר מגיעים ל-32 תהליכים בהם מבוצעת סריקת DPI גולמית המגיעה לשיא של 160Gbps.
איור 3 מציג את ההתקדמות בביצועים בעת הפעלת ספריית HyperScan נגד מערך משותף של חתימות ובזרם של נתונים, אבל המעבד בפועל משתנה. כל הפלטפורמות היו מבוססות מערכות עם תושבת כפולה וארבע ליבות (סה"כ 8 ליבות). על ידי שימוש באותה ספריית HyperScan עם אותן APIs על מעבדים שונים במשפחת IA, ביצועי סריקת הגלם יכולים לעלות או לרדת בקלות יחסית בהתאם לביצועי הציוד הרצויים ורמת המחיר.
סיכום
יצרני ציוד אבטחת הרשת צריכים לעתים קרובות לעשות פשרות כשמנסים לאחד את המוצרים שלהם על גבי פלטפורמה אחת. חומרה ותוכנה המיועדים לעיבוד קל יותר וסינון חבילות פשוט בציוד SOHO יכולים להיות שונים באופן משמעותי מאלה שתוכננו ליישומי אבטחה מתקדמים בארגון גדול. עם זאת, חיסכון בעלויות הפיתוח הראשוני ותחזוקת תוכנה מתמשכת הופכים את האיחוד למטרה כדאית. קבוצות פיתוח שעובדות במקביל על פיתוח מוצרים דומים על פלטפורמות שונות הוא לא דבר מעשי יותר בשל לחצים מהשוק לצמצום עלויות תוך כדי היכולת להמשיך ולהציע מוצרים חדשים במהירות. היצרנים, כתוצאה מכך, מחפשים פלטפורמות המספקות ביצועים צפויים ורמות גבוהות יותר של יכולת הרחבה וגמישות, כך שניתן להשתמש באותה תוכנה על כל המוצרים במשפחת המוצרים. הדבר אפשרי רק על ידי אימוץ פתרונות מבוססי תוכנה בלבד המנצלים עיבוד מרובה ליבות להגדלת או הקטנת של קו המוצרים מטיפול ב-Gbps בודדים ועד לציוד רשת רחב המטפל במספר גדול של Gbps.
ספריית HyperScan של Sensory Networks להתאמת תבניות מאפשרת ליישומי אבטחה מתקדמים לשדרג את ביצועי DPI שלהם בצורה לינארית עד ל-160Gbps. אותה הספרייה ניתנת לשימוש בציוד קטן יותר ובאותה עלות אפקטיבית כמו בציוד לרשתות גדולות בקנה מידה של ארגונים וזאת רק על ידי התאמת מספר תהליכי החומרה (h/w threads) של המעבדים.
עיבוד חבילות בפלטפורמות מבוססות
Intel Architecture
ישנן מספר סיבות לכך שתוכנה הרצה על פלטפורמות מבוססות Intel Architecture () יכולות להשיג ביצועי עיבוד מנות מעולות. אסטרטגית ה-tick-tock של אינטל שילוב מהיר של מיקרו-ארכיטקטורות חדשות ביחד עם שיפורים בטכנולוגיית התהליך (process) אפשרה למעבדי-IA מרובי ליבות לגדיל את ההובלה שלהם ביכולת העיבוד גם ב-Control Plane וגם ב-Data Plane.
החידושים האחרונים כוללים החלפת ערוץ הנתונים בצד הקדמי (FSB) בחיבור point-to-point Intel QuickPath, ריבוי-תהליכים סימטרי, תמיכה בגישה לזיכרון מסוגnon-uniform (), הטמעה של בקרי זיכרון רחבים יותר, כמו גם פקודות חדשות לזרמי נתונים לצורך חישובי CRC מהירים יותר. אינטגרציה הדוקה זו משפיעה ישירות בכך שחבילות מועברות מכרטיס הרשת לזיכרון המקומי ביעילות גבוהה יותר מאשר בעבר.
ברגע שהמנות נמצאות בזיכרון, תוכנת יישום יכולה להשתמש בטכנולוגיות – Intel® Data Plane Development Kit
() וב-Intel® QuickAssist כדי להאיץ את עיבוד חבילות בעזרת תכונות כמו זמן שידור וקליטה של חבילות ללא הפרעת פסיקות, יכולת ל-Pre-fetching ו-Cache Warming, מודעות ל-NUMA, ניהול Real-time buffers ו-Zero-copy buffers, lockless rings, התאמת Prefix הארוכה ביותר והאופטימלית ל-IA וסיווג תעבורה-flow classification. תכונות אלה יחד עם קצבי שעון גבוהים וזיכרונות מטמון גדולים במעבדי IA, הופכות פלטפורמות IA מרובי-ליבות למתאימות במיוחד ליישומי High Touch ו-Low Touch המאפשרות יכולות עיבוד חבילות המובילות בשוק, כמו גם האצת עומסי עבודה אינטנסיביים
ב-DataPath כגון הצפנה, דחיסה, ו-DPI.
מאת: אריק וינשטיין
