




 מאת: מיאנאק דאגה, אשווין אמ. אג’י, וו-צ’ון פנג, המכון הפוליטכני של וירג’יניה
מאת: מיאנאק דאגה, אשווין אמ. אג’י, וו-צ’ון פנג, המכון הפוליטכני של וירג’יניה
תקציר – יחידות העיבוד הגרפי (GPU) התקדמו בצעדים גדולים והפכו להיות מאיצים בתחום המחשוב המקבילי. ואולם, מאחר שיחידות GPU היו עד עתה יחידות בדידות שהתחברו באמצעות אפיק PCIe, הביצועים של יישומי GPU היו נתונים תחת אפשרות של פגיעה כתוצאה מצוואר הבקבוק שנוצר בהעברת הנתונים בין יחידת העיבוד המרכזית, CPU, לבין יחידת העיבוד הגרפי, (GPU), דרך ממשק PCIe. ארכיטקטורות מחשוב הטרוגניות אשר “ממזגות” את הפונקציונליות של CPU עם זו של יחידת GPU, כמו למשל Fusion של חברת AMD או Knights Ferry של Intel, נושאות את ההבטחה למציאת פתרון לצוואר הבקבוק האמור של ממשק PCIe.
במאמר זה אנו מאפיינים ומנתחים באופן ניסיוני את יעילותו של המעבד Fusion של AMD, שהוא בעל ארכיטקטורה שמשלבת באותו השבב ליבות x86 רב תכליתיות עם ליבות מאיצות הניתנות לתכנות. אנו מאפיינים את הביצועים של המעבד בעזרת מערך של מבחני ביצועים זעירים (כגון העברת נתונים דרך PCIe), מבחני ביצועים של הגרעין (kernel) (כגון פעולת חיסור) ובעזרת יישומים ממשיים (לדוגמה דינמיקה מולקולרית). בתלות במבחן הביצועים, התוצאות שלנו מראות שהמעבד Fusion מגיע לשיפור זמני העברת הנתונים המגיע לפי 1.7 עד פי 6.0 יותר בהשוואה ליחידת GPU בדידה. כתוצאה מכך, שיפור זה בביצועי העברת הנתונים יכול להגדיל באופן משמעותי את ביצועי היישום. לדוגמה, בהפעלה של מבחן ביצועים של פעולת חיסור באמצעות Fusion של AMD שבו יש 80 ליבות GPU בלבד התקבל שיפור של פי 3.5 לעומת יחידת GPU הבדידה Radeon HD 5870 של AMD שבה יש 1600 ליבות GPU בעלות יכולת רבה יותר.
הקדמה
העובדה שמחשבים שולחניים ותחנות עבודה אימצו במידה רבה את יחידות העיבוד הגרפי (GPU) בעלות יכולת חישוב, הפכה אותן ליחידות שמתאימות לשמש כמאיצים עבור מחשוב מקבילי בביצועים גבוהים. הפופולריות הגוברת שלהן, נובעת בין השאר מהמיזוג הייחודי של ביצועים, יכולות ונצילות אנרגיה. למעשה, בשלושה מבין חמשת מחשבי העל המובילים בעולם השתמשו ביחידות GPU, כך על פי Top500.
ובכל זאת, מבט מעמיק יותר ברשימה של Top500 מגלה שמחשבי העל הפועלים עם יחידות GPU משיגים רק 50 אחוזים, בערך, מביצועי השיא התיאורטיים שלהם, בהשוואה למחשבי על שאינם פועלים עם יחידות GPU ומגיעים ל–78 אחוזים מהשיא התיאורטי שלהם. מצב זה מרמז על כך שקיימים היבטים מסוימים של יחידות GPU שמגבילים את הביצועים שלהם עבור בדיקת Linpack, מבחן הביצועים שמשמש לצורך דירוג מחשבי העל ברשימת Top500. מאחר שיחידות העיבוד הגרפי היו באופן מסורתי מחוברות עד כה דרך אפיק PCI Express (PCIe), חלו “עלויות” תקורה נוספות על פעולות העברת הנתונים מהמחשב המארח אל יחידת GPU וכן בכיוון ההפוך. כתוצאה מכך, נוצרים לא פעם צווארי בקבוק ביישומי GPU כתוצאה מפעולות הכרוכות בהעברת הנתונים דרך אפיק PCIe. לכן, יחידות העיבוד הגרפי אינן ככלות הכל, תרופת הפלא המרפאה את הכל.
עם הופעתן של ארכיטקטורות המחשוב ההטרוגניות אשר משלבות את הפונקציונליות של יחידת העיבוד המרכזית – CPU עם הפונקציונליות של יחידת העיבוד הגרפי – GPU, כדוגמת Fusion של AMD ו-Knights Ferry של Intel, קיימת ציפייה למציאת פתרון לבעיית צווארי הבקבוק של אפיק PCIe. בארכיטקטורות אלו, ליבות x86 וליבות GPU הניתנות לתכנות, חולקות נתיב משותף אל זיכרון המערכת. כמו כן קיימים בהן מנועים מהירים להעברת בלוקים של נתונים, אשר מסייעים בהעברת הנתונים בין ליבות x86 לבין ליבות GPU. לכן פעולות הכרוכות בהעברת נתונים, לעולם אינן קשורות לאפיק החיצוני של המערכת, ומכאן שארכיטקטורות אלו יכולות להתמודד עם ההשפעות השליליות של אפיק PCIe האיטי.
במאמר זה אנו מציגים את האפיון הניסיוני ואת ניתוח היעילות של ארכיטקטורת Fusion של AMD. למיטב ידיעתנו, זו העבודה הראשונה המביאה נתונים אלו. המעבד הבנוי על ארכיטקטורת Fusion מכונה “יחידת עיבוד מואץ” (APU). יחידת APU משלבת ליבות x86 רב תכליתיות עם מנועי עיבוד וקטוריים ניתנים לתכנות של יחידת GPU בתוך שבב סיליקון יחיד. לאחר מכן, השתמשנו בחוק אמדל (Amdahl’s Law) המותאם לעידן המעבדים המואצים של ימינו. במיוחד, הראינו שליבות ה- CPU והליבות של יחידת GPU המשולבות יחד, איפשרו קבלת ביצועים טובים יותר מאשר אלו שהתקבלו עם יחידת GPU, ואף טובים יותר מאלו שהתקבלו עם CPU מסורתיים בריבוי ליבות, על ידי הקטנת התקורה המקבילית של פעולות העברת הנתונים באפיק PCIe.
על מנת לאפיין את הביצועים של ארכיטקטורת Fusion של AMD, השתמשנו בארבעה מבחני ביצועים מתוך סוויטת מבחני הביצועים “מחשוב הטרוגני מדורג” (SHOC), וכן במבחן לבדיקת רוחב הפס של אפיק PCIe באמצעות OpenCL. בעזרת מבחני ביצועים אלו הראינו שהארכיטקטורה של Fusion יכולה להתגבר על צוואר הבקבוק הנוצר על ידי PCIe בשימוש עם יחידת GPU נפרדת, אם כי לא תמיד.
עבור הדור הראשון של Fusion של AMD, יחידת APU שהיא שילוב של CPU עם יחידת GPU סיפקה ביצועים טובים יותר מאלו שהתקבלו על ידי שילוב של CPU עם יחידת GPU נפרדת, כאשר כמות הנתונים שהיה צורך להעביר בין CPU לבין יחידת GPU עלתה על סף מינימלי כלשהו, וכאשר כמות פעולות המחשוב בליבות של יחידת GPU לא הייתה גבוהה במידה מספקת על מנת לשחוק את התקורה של העברת הנתונים דרך אפיק PCIe.
התוצאות הניסיוניות שלנו מראות שיחידת APU שיפרה את הזמנים הנדרשים להעברת הנתונים, שיפור של פי 1.7 עד פי 6.0 לעומת שילוב של CPU עם יחידת GPU נפרדות. עבור מבחן ביצועים מסוים, כלומר עבור פעולת חיסור, זמן הביצוע הכולל של יחידת APU מסוג Fusion היה טוב פי 3.5 יותר מאשר זמן הביצוע של יחידת GPU הבדידה, על אף שלזו האחרונה היו פי 20 יותר ליבות GPU והליבות היו בעלות יכולת רבה יותר. כתוצאה מכך, השיפור בזמנים הכרוך בהעברת הנתונים מקטין את התקורה של פעולה מקבילית, ולכן מספק ליישום יכולת גבוהה יותר של מקבילות.
המשכו של המאמר מאורגן באופן הבא. פרק 2 מציג סקירה כללית של יחידות העיבוד הגרפי של AMD ואת הבעיה של צוואר הבקבוק באפיק PCIe הנוצר בפלטפורמות של CPU עם יחידת GPU נפרדת. לאחר מכן, נציג את ארכיטקטורת של Fusion של AMD ונתאר כיצד היא מקיימת את ההבטחה, לפיה אפשר להתגבר על צוואר בקבוק זה. בפרק III נחזור ונתאר את חוק אמדל עבור מעבדים מבוססי מאיצים. בפרק IV נתאר את תוצאות הניסויים שלנו ונדון בהם. פרק V נציג עבודה קשורה לעניינינו, ולסיום, בפרק VI, נסכם את המסקנות ונסביר על עבודה עתידית.
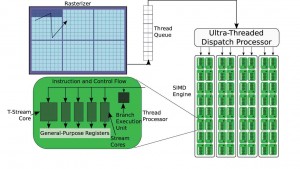
איור 1. מבט כללי מעבד זרימה ומתזמן תהליכונים של AMD–ATI.
רקע
בחלק זה נציג סקירה כללית של יחידות GPU של AMD ונדון בהשפעתו של צוואר הבקבוק שנגרם על ידי אפיק PCIe, אשר לא פעם הוכח שהוא מהווה מכשול בדרך להשגת ביצועים כוללים טובים יותר של היישום. לאחר מכן נתאר את הארכיטקטורה של הדור הראשון של יחידות עיבוד מואץ (APU), כלומר יחידת APU בסדרה G מסוג Fusion של AMD, ונראה כיצד ההבטחה להתגבר על צוואר הבקבוק של אפיק PCIe מתקיימת.
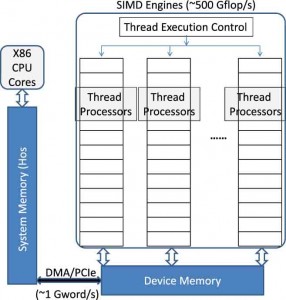
איור 2. המבנה של יחידת GPU בדידה
א. סקירה כללית של יחידות GPU של AMD
יחידת GPU של AMD הולכת בעקבות התכנון הקלאסי של יחידות גרפיות, המותאם במידה רבה לאריתמטיקה בנקודה צפה בדיוק יחיד, ולפעולות נפוצות הקשורות לתמונות בנתונים דו ממדיים ובנתוני תמונה. איור 1 מספק מבט כללי של הארכיטקטורה.
במקרה זה יחידת החישובים ידועה בשם מנוע SIMD, והיא מכילה כמה Thread Processors, כל אחד מהם מכיל ארבע ליבות זרימה עם ליבה ייעודית ויחידת ביצוע פקודות הסתעפות (branch execution). הליבה הייעודית (או T-Stream) מתוכננת לבצע בחומרה פונקציות מתמטיות מסוימות, לדוגמה פונקציות טרנסדנטיות כדוגמת סינוס – sin(), קוסינוס – cos() וטנגנס – tan(). מאחר שקיימת רק יחידה אחת לביצוע פקודות הסתעפות, לכל הסתעפות בתוכנית יש עלות שבאה לידי ביטוי בצורת מעבר לפעולה טורית, כדי לקבוע את הנתיב שבו יעבור כל Thread. הביצוע של הסתעפויות מתפלגות, מתבצע באופן של “צעדים נעולים” (lock–step) עבור כל הליבות הקיימות ביחידת החישוב. בנוסף, ליבות העיבוד הן מעבדים וקטוריים ומשמעות עובדה זו היא שהשימוש בסוגי וקטור יכול להפיק האצה ממשית ביחידות GPU של AMD.
ביחידות GPU בדידות של חברת AMD קיים מספר גדול מאוד של ליבות עיבוד, בטווח שבין 800 ל-1,600 ליבות. כתוצאה מכך, יש צורך להפעיל מספר אחיד של Threads על מנת לשמור את כל הליבות שביחידת GPU במצב פועל. עם זאת כדי להפעיל מספר רב של Threads, יש להקפיד שכמות האוגרים (register) המשמשים כל של Thread תהיה מינימלית. כלומר, יש לאחסן את כל האוגרים המשמשים לפעולתו של תהליכון אחד בקובץ אוגרים, ולכן יוגבל המספר הכולל של כל של Threads שאותם אפשר לתזמן על ידי הגודל של קובץ האוגרים, שהוא גודל נדיב של 256KB בדור האחרון של יחידות GPU של AMD.
תכונה מבנית ייחודית נוספת של יחידות GPU של AMD היא שימוש ביוצר רשת גרפית (rasterizer) לצורך ביצוע פעולות עם מטריצות דו ממדיות של תהליכונים ונתונים. מכאן, הגישה לאלמנטים סקלריים המאוחסנים באופן רציף (contiguously) בזיכרון אינה תבנית הגישה היעילה ביותר. הגישה לאלמנטים סקלריים יכולה להתבצע בדרך קצת יותר יעילה, והיא על ידי גישה בנתחים של 128 סיביות בשל השימוש בליבות ווקטוריות. הטעינה של נתחים אלו מזיכרון תמונה, אשר משתמש במבנה הזיכרון המתאים ביותר לחומרת הזיכרון שביחידות GPU של AMD, שגם הוא מניב שיפור משמעותי בביצועים.
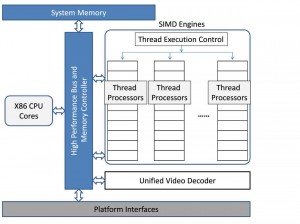
איור 3. המבנה של יחידת AMD FUSION APU
ב. צווארי הבקבוק של PCIe בשימוש ביחידות GPU בדידות
באיור 2 אנו מדגימים את הסיבה לקיומם של צווארי הבקבוק של PCIe בשימוש עם יחידות GPU בדידות. כפי שאפשר לראות, יחידת CPU המארחת x86 יכולה לגשת לזיכרון המערכת, ובמקביל גם לאתחל את הפעלתן של פונקציות הקיימות ביחידת GPU. עם זאת, מאחר שיחידת GPU מחוברת דרך אפיק PCIe, נדרשת גישת DMA כדי להעביר נתונים מזיכרון המערכת של CPU אל זיכרון ההתקן של יחידת GPU, על מנת לבצע כל פעולה שימושית. למרות שיחידת GPU יכולה לבצע מאות מיליארדי פעולות בנקודה צפה בשנייה, החיבורים הפנימיים שקיימים כיום עבור אפיק PCIe יכולים להעביר רק ג’יגה-מילה אחת בערך, בשנייה. כתוצאה ממגבלה זו, מתכנת היישומים של יחידת GPU חייב להבטיח מיחזור נתונים ברמה גבוהה ביחידת GPU כדי שיוכל להקטין בהצלחה את העלות הכרוכה בפעולות ההעברה האיטיות באפיק PCIe, ובכך להצליח בהשגת יתרונות ניכרים בביצועים.
ועם זאת, ייתכן שלא תהיה אפשרות להבטיח בכל היישומים מיחזור נתונים ברמה גבוהה. לדוגמה, ייתכן שיהיו יישומים כאלו שבהם זמן הביצוע ביחידת GPU יהיה פחות מהזמן שנמשכת הבאה של הנתונים אל יחידת GPU, או יישומים שפרופילי הביצוע שלהם מבוססים על פעולות חוזרות של העברה בגישת DMA ושל ביצוע ביחידת GPU. עבור יישומים מסוג זה, ייתכן שהשימוש ביחידות GPU אינו מתאים להאצת הביצועים.
בארכיטקטורות חדשות, כמו זו של Fusion של AMD, נעשה ניסיון לפתור את הבעיות האלו, על ידי ביטול הגישה אל יחידת GPU דרך אפיק PCIe באמצעות “מיזוג” הפונקציונליות של CPU עם הפונקציונליות של יחידת GPU בשבב סיליקון יחיד.
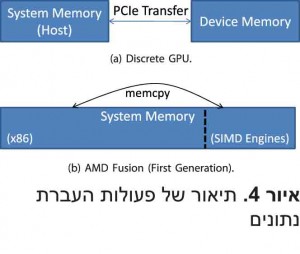
ג. הארכיטקטורה של Fusion של AMDברמה הבסיסית ביותר הארכיטקטורה של Fusion משלבת ליבות מעבדים סקלריות ווקטוריות רב תכליתיות בשבב סיליקון יחיד, ועל ידי כך יוצרת מעבד מחשוב הטרוגני. המטרה שלו היא לספק תרחיש של “הטוב ביותר משני העולמות” במובן שעומסי העבודה הסקלריים, כגון עיבוד תמלילים או גלישה ברשת, ישתמשו בליבות x86 ולעומתם, עומסי העבודה הווקטוריים, כדוגמת עיבוד נתונים מקבילי, ישתמשו בליבות של יחידת GPU.איור 3 מתאר תרשים בלוקים של ארכיטקטורה חדשנית זו. ההיבט החשוב הראוי לתשומת לב הוא העובדה שליבות CPU x86 והמנועים הווקטוריים (SIMD) מחוברים לזיכרון המערכת דרך אותם אפיק מהיר ובקר זיכרון. אמצעי מבני זה מאפשר לארכיטקטורה של Fusion של AMD לשחרר את המגבלה הבסיסי של אפיק PCIe, זו אשר הגבילה באופן מסורתי את הביצועים בשימוש ביחידת GPU בדידה. מלבד ליבות העיבוד, Fusion מורכב גם ממרכיבי המערכת הבאים: בקר זיכרון, בקר כניסות ויציאות (I/O), מפענח קידוד וידיאו, יציאה לתצוגה וממשקי אפיקים - הכל באותו השבב.למרות שליבות x86 של Fusion ומנועי SIMD שלו חולקים אפיק משותף אל זיכרון המערכת, המימוש בדור הראשון של Fusion מחלק את זיכרון המערכת לשני חלקים - האחד הגלוי למערכת ההפעלה שפועלת בליבות x86 ומנוהל על ידה, והשני המנוהל על ידי התוכנה שפועלת במנועי SMID. לכן, אפילו בארכיטקטורה של Fusion, יש להעביר נתונים מהחלק של מערכת ההפעלה שקיים בזיכרון המערכת אל החלק הגלוי למנועי SMID. אך עם זאת, בניגוד ליחידות GPU נפרדות, שבהן פעולות העברה אלו של נתונים מזיכרון המערכת אל זיכרון ההתקן עוברות דרך אפיק PCIe, צפוי שפעולות ההעברה של נתונים ביחידת Fusion יסתכמו ב-memcpy, כפי אפשר להבין באופן לוגי מאיור 4. בנוסף, חברת AMD מספקת כיום מנועים מהירים להעברת בלוקים אשר מעבירים נתונים בין מחיצת הזיכרון של x86 לבין מחיצת הזיכרון של SMID. לכן הארכיטקטורה של Fusion נושאת את ההבטחה של שיפור הביצועים עבור כל היישומים שקודם לכן היו בהם צווארי בקבוק בעטיין של פעולות ההעברה דרך אפיק PCIe. צפוי שבארכיטקטורות עתידיות של יחידות APU והזיכרונות האלה יתמזגו באופן חלק, והמשמעות היא, שלא יהיה כלל צורך בהעברת נתונים אל זיכרון יחידת GPU וממנו.התכנות של Fusion נעשה פשוט וקל יותר בעזרת תקן OpenCL המתפתח. לכן, יישומים קיימים שנכתבו לפי OpenCL עבור שילוב של CPU ויחידת GPU נפרדות יכולים לפעול ללא כל שינויים במיזוג של CPU עם יחידת GPU שביחידת Fusion. איור 5. אפיון של התקורה המקבילית
שימוש בחוק אמדל
ראשית נסקור בקצרה את חוק אמדל (Amdahl), ולאחר מכן נערוך דיון תיאורטי על עבודתם של היל ומרטי בנוגע ליישום החוק על שבבים מרובי ליבות סימטריים ואסימטריים. לאחר מכן נחזור ונדון בחוק אמדל ובמיוחד בנוגע למאיצים, ונראה שליבות אסימטריות של יחידות CPU משולבת עם יחידות GPU, שיוצרות יחידת APU, מאפשרות קבלת מקבילות בקוד רבה יותר מזו שמתקבלת ביחידות GPU נפרדות או במעבדים סימטריים מסורתיים עם ליבות מרובות.
ההאצה של יישומים מקבילים בארכיטקטורות של מעבדים מרובים מוגבלת על ידי חוק אמדל, אשר מרמז שההאצה המושגת על ידי מימוש של יישום במקביל תלויה בחלק של עומס העבודה שאותו אפשר להפוך למקבילי. ההאצה S עבור יישום מקבילי נתונה בנוסחה הבאה (נוסחה 1).
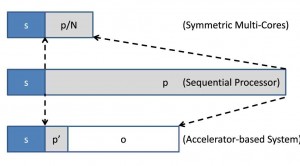
איור 6. יצירת מחיצות של הקוד עבור פלטפורמות שונות של תכנות מקבילי
1.
כאשר p = החלק המקבילי של היישום
s = החלק הטורי של היישום, כלומר
ו– N = מספר המעבדים
חוק אמדל נכון עבור תרחישים אידיאליים בכל מערכת של ריבוי מעבדים, אם אנו מניחים שעומס העבודה קבוע כלומר עם דירוג חזק. גם כאן קיימת ההנחה שלכל המעבדים יש אותן יכולות חישוביות כוללות.
אם N ← ∞ כי אז,
(2)
באופן לא רשמי, המשמעות היא שגם כאשר החלק הטורי של העבודה קטן, ההאצה המרבית שאפשר להשיג מממספר אינסופי של מעבדים מקבילים מוגבלת על ידי הערך של 1/s.
היל ומרטי סיווגו לראשונה שבבים בעלי ליבות מרובות לשלוש קבוצות, בהתבסס על האופן שבו משולבים משאבי היחידה שעל השבב או שווי הערך הבסיסיים של הליבה, ויוצרים ליבות עיבוד גדולות יותר. באופן מיוחד הם סיווגו את השבבים לשבבים סימטריים, שבבים אסימטריים ושבבים דינמיים בעלי ריבוי של ליבות, ולאחר מכן ניתחו באופן תיאורטי את מידת ההאצה שאפשר להשיג בכל פלטפורמה.
שבבים סימטריים הם השבבים המסורתיים בעלי ליבות מרובות, כאשר לכל אחד מהמעבדים יש יכולת חישובית זהה. אפשר להפעיל את משוואה (1) באופן ישיר על שבבים סימטריים עם ההשלכה שלפיה חיוני שהמתכנת יפיק מקבילות מהקוד שלהם.
שבבים דינמיים הם שבבים אידיאליים שבהם אפשר לשלב את הליבות באופן דינמי על מנת להאיץ את הביצועים של החלק הטורי שבתוכנית, ובכך לספק יעילות מרבית אף אם בקוד יש חלק טורי גדול למדי. במאמר זה לא נחקרים שבבים דינמיים. אך עם זאת, נשוב אליהם בעתיד על מנת לחקור את הדור הבא של יחידות APU בסדרה A של AMD, אשר מבטיחות את שיפור נצילות ההספק על ידי הפעלה וכיבוי דינמיים של משאבי CPU ויחידות GPU בתלות בעומס של היישום (מיתוג הספק מבית AMD).
ומן הצד האחר, שבבים אסימטריים הם אלה שיש בהם ליבה אחת גדולה ומורכבת עבור התוכניות הסדרתיות וכמה ליבות נוספות, פשוטות יותר, אשר מסייעות לליבה הגדולה יותר בעיבוד מקבילי. היל ומרטי הראו שליבות מרובות אסימטריות מציעות האצה פוטנציאלית גדולה יותר מזו המוצעת על ידי המתחרים הסימטריים שלהם, אף עבור ערכים נמוכים יותר של p. לדוגמה, הם הראו שעבור p=0.975 ו- N=256 ההאצה האסימטרית הטובה ביותר תהיה בשיעור של 125.0, לעומת ההאצה הסימטרית הטובה ביותר, שתהיה בשיעור של 51.2. עם זאת הם מניחים הנחה אידיאלית, לפיה החלק המקבילי של התוכנית מנצל באופן מלא את הליבות העומדות לרשותו. מצב כזה אפשרי רק אם קיים מנגנון מושלם של תזמון משותף אשר מאפשר ניצול מלא של המשאבים שעל השבב. יתר על כן, יש עדות לכך ששבבים אסימטריים בעלי ליבות מרובות יעילים יותר מאשר השבבים הסימטריים.
נבדוק עתה את חוק אמדל עבור מערכות מבוססות מאיצים שאליהם אפשר להתייחס כאל סוג מיוחד של ליבות מרובות אסימטריות, עם אפשרות להפריד את ליבות המאיצים מהמעבד הטורי באמצעות אפיק PCIe. באופן כללי, חוק אמדל מתעלם מהתקורה שנוצרת כתוצאה מהעברת עומס העבודה למקבילי. בכל מעבד בעל תקורות מרובות, תקורה זו נובעת בעיקרה מיצירתן של תהליכונים מקביליים, מהתקשורת שבין המעבדים ומהחיבור מחדש של התהליכונים. לכן, ההאצה המושגת תהיה תמיד פחותה מזו שקיימת במצב האידיאלי. מעבר לכך, התקורה הנוצרת על ידי העברת יישום למקבילי במערכת מבוסס מאיצים במיוחד ביחידת GPU גבוהה אף יותר, מאחר שיש להעביר את הנתונים דרך אפיק PCIe האיטי. עובדה זו מאוששת על ידי אחת מהתוצאות של מבחני הביצועים הזעירים שלנו, כפי שאפשר לראות באיור 5.
מבחן ביצועים זעיר מסוים מבצע פעולת fmad בין כל אחד מהערכים של שני מערכים מסוג float-type בגודל של 96 מגה ביית, כל אחד. פעולה זו מבוצעת בשלוש פלטפורמות שונות, כלומר CPU מודרני בעל ארבע ליבות, CPU ויחידת GPU בדידות (Radeon HD 5870 של AMD) ו-CPU עם יחידת GPU משולבת (יחידת APU מסוג Ontario/Zacate בסדרת G של AMD). השתמשנו בפלטפורמה OpenMP כבפלטפורמת התכנות המקבילי עבור המעבד בעל ארבע הליבות ובפלטפורמה OpenCL עבור יחידת GPU מסוג Radeon ועבור יחידת APU מסוג Ontario. המספרים מציגים את זמן הביצוע הכולל כסכום של: (i) זמן הביצוע של החלק הטורי, (ii) זמן הביצוע של החלק המקבילי, ו- (iii) התקורה הנוצרת כתוצאה ממעבר למקבילי, כלומר יצירת הזיכרון הזמני (buffer) של ההתקן, ההריסה שלו ולאחר מכן העברתו. (לא כללנו את זמן היצירה הקבוע של OpenCL כלומר, אתחול הידור הגרעין, התוכנית והפלטפורמה).
זמן הביצוע של “החלק המקבילי” במקרה של יחידת GPU בדידה ובמקרה של יחידת APU, הוא זמן ביצוע הגרעין. המימוש בתהליכון יחיד מתאר את החלק הטורי ואת החלק המקבילי של הקוד, ולעומתו, במקרה האידיאלי של חוק אמדל, החלק המקבילי מואץ פי ארבעה (CPU בעל ארבע ליבות) עם תקורה השווה אפס. אמנם המימוש האמיתי של ריבוי ליבות אשר מועבר למקבילי באמצעות OpenMP כולל תקורה מקבילית, אך תקורה זו זניחה בהשוואה לתקורה הנוצרת מהעברה למקבילי בפלטפורמות המואצות.
עם זאת, עבור יחידת GPU הבדידה, התקורה המקבילית משמעותית כל כך, עד כי היא מהווה יותר מאשר סכום זמני הביצוע של החלק הטורי והחלק המקבילי. אם כן, אמנם זמן הביצוע של החלק המקבילי ביחידת GPU הבדידה באופן משמעותי טוב יותר מזמן הביצוע ב- CPU בעל ריבוי ליבות, אך התקורה גדולה יותר בהרבה, עד כי אין היא הופכת את מבחן הביצועים לנוח עבור העיבוד ביחידת GPU. מצב זה גם מדגים את צוואר הבקבוק שנגרם על ידי התקשורת דרך אפיק PCIe.
לבסוף, יחידת APU (או CPU משולב עם יחידת GPU) מסייעת בהפחתת התקורה המקבילית. עם זאת כתוצאה מהנוכחות של ליבות SIMD, שהן בעלות יכולת חישובית קטנה יותר, זמן הביצוע של החלק המקבילי ארוך יותר מאשר זמן הביצוע ביחידת GPU נפרדת.
על מנת ליישם את חוק אמדל על פלטפורמות מבוססות מאיצים יצרנו מודל של שני הגורמים הבאים:
חלק מקבילי מואץ (‘p): עבור מעבדים מסורתיים סימטריים בעלי ליבות מרובות, החלק המקבילי p היה באופן אידיאלי מותאם באופטימיזציה ל-p/N. עם זאת, לליבות מאיצים יש יכולות חישוביות שונות מאוד מאשר לליבות הטוריות, לכן השימוש במונחים p ו-N במשוואה יהיה חסר משמעות. הביצועים הממשיים במאיצים יכולים להשתנות בתלות באופן שבו ממפים את האלגוריתם אל הליבות שלו. על כן, שינינו את הביצועים של החלק המקבילי p ל-’p, כפי שאפשר לראות באיור 6. שים לב ש-’p יכול להיות גדול יותר מ- p במקרים של מיפוי גרוע.
התקורה המקבילית (o): עבור מעבדים מסורתיים סימטריים בעלי ליבות מרובות התקורה המקבילית (o) תהיה בדרך ככל זניחה, בהינתן העובדה שהתקשורת בין מעבדים בדרך כלל מועטה. עם זאת, עבור פלטפורמות מבוססות מאיצים התקורה המקבילית o מרכיבה חלק משמעותי של התוכנית כתוצאה מהתקורה של העברת הנתונים בין זיכרון CPU לבין הזיכרון של ההתקן (יחידת GPU).
לכן אפשר להציג את ההאצה החדשה S’ עבור יישומים מקביליים לפי המשוואה:
3.
כאשר: ‘p = החלק המקבילי המואץ
o = התקורה המקבילית
עדיין חשוב למצוא בקוד מקבילות במידה שתספיק על מנת להקטין למינימום את s, כדי שאפשר יהיה להגדיל למקסימום את החלק המקבילי בתוכנית. עם זאת, מאחר שליחידות GPU בדידות יש תקורה מקבילית o גדולה, היתרון של המקבילות המופקת p’ מוקטן כתוצאה מכך במידה רבה. מצד שני, התקורה המקבילית o של Fusion של AMD קטנה יותר בהרבה ועל כן היא תביא תועלת רבה יותר מחלק מקבילי גדול יותר בקוד. ארכיטקטורות כדוגמת Fusion של AMD דומות יותר למעבדים אסימטריים אמיתיים בעלי ליבות מרובות עם ניצול משאבים ויעילות רבים יותר בהרבה, כפי שנטען על ידי היל ומרטי.
בסיכום, Fusion של AMD אמור לספק ביצועים טובים יותר מאשר יחידת GPU בדידה עם יחידות חישוב SIMD שוות ערך, אם המקבילות המופקת p’ נותרת אותה האחת, מאחר שהתקורה המקבילית o קטנה יותר באופן יחסי כאשר משווים אותה למקבילה שלה בשימוש ביחידת GPU בדידה. עם זאת, בפועל, החלק המקבילי p’ יכול להיות גדול יותר עבור יישומים תלויי זיכרון הפועלים בפלטפורמת APU מאחר שרוחב הפס של הזיכרון ביחידות CPUמסורתיות קטן יותר מאשר אותו רוחב פס ביחידות GPU בדידות. כתוצאה מכך, אפשר לצפות שניתן יהיה להשיג האצה S’ טובה יותר ביחידת Fusion של AMD בתנאי שממשק הזיכרון אל ליבות SIMD מהיר באותה מידה כמו הממשק ביחידת GPU בדידה.
עם זאת, האם יחידות GPU הן תרופת הפלא לכל הבעיות? האם יחידות GPU יעלו תמיד בביצועיהן על יחידות CPUבעלות ליבות מרובות? התשובה תלויה ביישום, בסוג יחידת GPU, ובאסטרטגיית התזמון המשולב (p’). ארכיטקטורות כדוגמת Fusion של AMD הן צעד בכיוון הנכון, מאחר שהתוצאות המוצגות באיור 5 הן חיזוק רציני לטובת הארכיטקטורה החדשנית הזו. אם ליחידת APU מצורפים מנועי SIMD בעלי יכולת גדולה יותר וממשקי זיכרון מהירים כמו שיש ביחידות GPU בדידות, כי אז הביצועים של היישומים המואצים רק יוסיפו וישתפרו בעזרת פלטפורמות ממוזגות אלו.
*המשך בגליון הבא.
הכתבה באדיבות אתר: http://synergy.cs.vt.edu/publications.php
