



מספר פריצות דרך טכנולוגיות של חוקרי אנבידיה ישראל מאפשרות לאמן יישומי "טקסט לתמונה" (Text-to-Image) להשתמש בתמונות של אובייקטים ספציפיים ולשלב אותם ביצירת תוכן ויזואלי באמצעות בינה מלאכותית יוצרת (Generative AI). אחד מהמחקרים יאפשר לבצע זאת עם תמונה אחת בלבד, בתהליך של שניות ספורות
קבוצת חוקרים ממרכז המחקר והפיתוח של אנבידיה בישראל, בשיתוף חוקרים מאוניברסיטת תל-אביב, חושפים מספר מחקרים ומודלים שיאפשרו את פיתוח הדור הבא של יישומיי בינה מלאכותית יוצרת (Generative AI) ליצירת תמונות, וידאו ותוכן תלת-ממדי דוגמת DALL-E2, MidJourney ואחרים.
המחקרים יוצגו, בין היתר, בכנס SIGGRAPH 2023 באוגוסט הקרוב, שם תחשוף אנבידיה שורה של מחקרים חדשים ופורצי דרך שיאפשרו לאמנים ומפתחים להפיח חיים ברעיונות שלהם. הפיתוחים החדשים יהיו זמינים למפתחים, וישולבו במוצרים עתידיים, בהם NVIDIA Omniverse, מודל הבינה היוצרת NVIDIA Picasso ועוד.

התאמה אישית מלאה: השלב הבא במודלי Generative AI ליצירת תמונות
מודלי בינה מלאכותית יוצרת שזמינים כיום שמסוגלים להפוך טקסט לתמונות הם כלים עוצמתיים שמאפשרים ליצור קונספט עיצובי או סטוריבורד (Storyboard) לסרטים, משחקי וידאו, ועוד – באמצעות מספר מילים או משפטים בלבד. עם זאת, לאמנים עשויים להיות רעיונות ספציפיים אותם הם ירצו לממש.
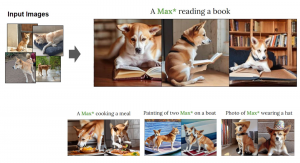
כך, לדוגמה, מנהל קריאייטיב בחברת צעצועים שמעוניין לתכנן קמפיין שיווקי סביב דובון צעצוע שהחברה מייצרת, היה רוצה לשלב את אותו דובון מסוים בתמונות של תרחישים שונים בקמפיין. על מנת לאפשר את ההתאמה האישית והספציפית הזו בתוצרי מודלי בינה מלאכותית יוצרת, חוקרי אנבידיה ישראל ואוניברסיטת תל-אביב פיתחו מספר מחקרים חדשים שיאפשרו למשתמשים לספק למערכות בינה יוצרת דוגמאות שהמודל יכול ללמוד במהירות.
באמצעות המודל החדש, החוקרים הצליחו "ללמד" את הבינה המלאכותית היוצרת לייצר תמונות של חפצים ספציפיים – למשל תמונה של מוצר, בעל חיים או פרט אישי. כך למשל, ניתן לבקש מהיישום להשתמש בתמונה של דובון צעצוע ספציפי, ולבקש ליצור תמונות של תרחישים שונים ומותאמים אישית, של אותו הדובון בדיוק.
פריצת הדרך הזו מאפשרת פרסונליזציה מלאה של תהליך הפקת תוצרים ויזואליים באמצעות בינה מלאכותית, תוך הענקת שליטה על התוצרים, ופותחת פתח למגוון רחב של שימושים עבור יוצרים, מעצבים, אנשי שיווק ומיתוג, יוצרים ומעצבים בעולם הגיימינג והמטאברס, עולם הבידור ואף העולם העסקי והמסחרי.
הכניסו תמונה אחת, וקבלו תוך שניות אינספור תוצרים מותאמים אישית
באחד המאמרים, החוקרים הדגימו כיצד ניתן לאמן את המודל להשתמש בתמונת-דוגמה אחת בלבד – כדי ללמוד קונספט חדש בו ניתן להשתמש בתוצרי יישום הבינה המלאכותית, ובנוסף להאיץ את התהליך עד לכדי שניות ספורות בלבד – מהיר פי 60 בהשוואה לגישות פרסונליזציה קודמות. במאמר נוסף, גם הוא מבית חוקרי אנבידיה, מציגים החוקרים מודל חדש וקל משקל בשם Perfusion אותו ניתן ללמד "להכיר" מספר אובייקטים נפרדים, ובאמצעותם לייצר קונספטים חדשים ומשולבים.
המודלים והמחקרים החדשים הללו יוצגו במסגרת כנס הגרפיקה הממוחשבת SIGGRAPH 2023 בקיץ הקרוב, כחלק מעשרות מחקרים חדשים בתחום שביצעה קבוצת המחקר של אנבידיה ברחבי העולם.
פיתוחים כגון אלה יוכלו לסייע ליוצרים במיזמי אמנות, ארכיטקטורה, עיצוב גרפי, פיתוח משחקים וסרטים לייצר במהירות רבה יותר דימויים באיכות גבוהה, ולאפשר למפתחים וארגונים לייצר באופן יעיל ומהיר דאטה סינתטי מותאם אישית עבור עולמות וירטואליים (Metaverse), לצרכים תעשייתיים, הטמעת רובוטים בתעשייה, אימון רכבים אוטונומיים ועוד.










